Archive for the ‘Bias’ Category
On the interpretation of probabilities in project management
Introduction
Managers have to make decisions based on an imperfect and incomplete knowledge of future events. One approach to improving managerial decision-making is to quantify uncertainties using probability. But what does it mean to assign a numerical probability to an event? For example, what do we mean when we say that the probability of finishing a particular task in 5 days is 0.75? How is this number to be interpreted? As it turns out there are several ways of interpreting probabilities. In this post I’ll look at three of these via an example drawn from project estimation.
Although the question raised above may seem somewhat philosophical, it is actually of great practical importance because of the increasing use of probabilistic techniques (such as Monte Carlo methods) in decision making. Those who advocate the use of these methods generally assume that probabilities are magically “given” and that their interpretation is unambiguous. Of course, neither is true – and hence the importance of clarifying what a numerical probability really means.
The example
Assume there’s a task that needs doing – this may be a project task or some other job that a manager is overseeing. Let’s further assume that we know the task can take anywhere between 2 to 8 days to finish, and that we (magically!) have numerical probabilities associated with completion on each of the days (as shown in the table below). I’ll say a teeny bit more about how these probabilities might be estimated shortly.
| Task finishes on | Probability |
| Day 2 | 0.05 |
| Day 3 | 0.15 |
| Day 4 | 0.3 |
| Day5 | 0.25 |
| Day 6 | .15 |
| Day 7 | .075 |
| Day 8 | .025 |
This table is a simple example of what’s technically called a probability distribution. Distributions express probabilities as a function of some variable. In our case the variable is time.
How are these probabilities obtained? There is no set method to do this but commonly used techniques are:
- By using historical data for similar tasks.
- By asking experts in the field.
Estimating probabilities is a hard problem. However, my aim in this article is to discuss what probabilities mean, not how they are obtained. So I’ll take the probabilities mentioned above as given and move on.
The rules of probability
Before we discuss the possible interpretations of probability, it is necessary to mention some of the mathematical properties we expect probabilities to possess. Rather than present these in a formal way, I’ll discuss them in the context of our example.
Here they are:
- All probabilities listed are numbers that lie between 0 (impossible) and 1 (absolute certainty).
- It is absolutely certain that the task will finish on one of the listed days. That is, the sum of all probabilities equals 1.
- It is impossible for the task not to finish on one of the listed days. In other words, the probability of the task finishing on a day not listed in the table is 0.
- The probability of finishing on any one of many days is given by the sum of the probabilities for all those days. For example, the probability of finishing on day 2 or day 3 is 0.20 (i.e, 0.05+0.15). This holds because the two events are mutually exclusive – that is, the occurence of one event precludes the occurence of the other. Specifically, if we finish on day 2 we cannot finish on day 3 (or any other day) and vice-versa.
These statements illustrate the mathematical assumptions (or axioms) of probability. I won’t write them out in their full mathematical splendour, those interested in this should head off to the Wikipedia article on the axioms of probability.
Another useful concept is that of cumulative probability which, in our example, is the probability that the task will be completed by a particular day . For example, the probability that the task will be completed by day 5 is 0.75 (the sum of probabilities for days 2 through 5). In general, the cumulative probability of finishing on any particular day is the sum of probabilities of completion for all days up to and including that day.
Interpretations of probability
With that background out of the way, we can get to the main point of this article which is:
What do these probabilities mean?
We’ll explore this question using the cumulative probability example mentioned above, and by drawing on a paper by Glen Shafer entitled, What is Probability?
OK, so what is meant by the statement, “There is a 75% chance that the task will finish in 5 days.” ?
It could mean that:
- If this task is done many times over, it will be completed within 5 days in 75% of the cases. Following Shafer, we’ll call this the frequency interpretation.
- It is believed that there is a 75% chance of finishing this task in 5 days. Note that belief can be tested by seeing if the person who holds the belief is willing to place a bet on task completion with odds that are equivalent to the believed probability. Shafer calls this the belief interpretation.
- Based on a comparison to similar tasks this particular task has a 75% chance of finishing in 5 days. Shafer refers to this as the support interpretation.
(Aside: The belief and support interpretations involve subjective and objective states of knowledge about the events of interest respectively. These are often referred to as subjective and objective Bayesian interpretations because knowledge about these events can be refined using Bayes Theorem, providing one has relevant data regarding the occurrence of events.)
The interesting thing is that all the above interpretations can be shown to satisfy the axioms of probability discussed earlier (see Shafer’s paper for details). However, it is clear from the above that each of these interpretations have very different meanings. We’ll take a closer look at this next.
More about the interpretations and their limitations
The frequency interpretation appears to be the most rational one because it interprets probabilities in terms of results of experiments – I.e. it interprets probabilities as experimental facts, not beliefs. In Shafer’s words:
According to the frequency interpretation, the probability of an event is the long-run frequency with which the event occurs in a certain experimental setup or in a certain population. This frequency is a fact about the experimental setup or the population, a fact independent of any person’s beliefs.
However, there is a big problem here: it assumes that such an experiment can actually be carried out. This definitely isn’t possible in our example: tasks cannot be repeated in exactly the same way – there will always be differences, however small.
There are other problems with the frequency interpretation. Some of these include:
- There are questions about whether a sequence of trials will converge to a well-defined probability.
- What if the event cannot be repeated?
- How does one decide on what makes up the population of all events. This is sometimes called the reference class problem.
See Shafer’s article for more on these.
The belief interpretation treats probabilities as betting odds. In this interpretation a 75% probability of finishing in 5 days means that we’re willing to put up 75 cents to win a dollar if the task finishes in 5 days (or equivalently 25 cents to win a dollar if it doesn’t). Note that this says nothing about how the bettor arrives at his or her odds. These are subjective (personal) beliefs. However, they are experimentally determinable – one can determine peoples’ subjective odds by finding out how theyactually place bets.
There is a good deal of debate about whether the belief interpretation is normative or descriptive: that is, do the rules of probability tell us what people’s beliefs should be or do they tell us what they actually are. Most people trained in statistics would claim the former – that the rules impose conditions that beliefs should satisfy. In contrast, in management and behavioural science, probabilities based on subjective beliefs are often assumed to describe how the world actually is. However, the wealth of literature on cognitive biases suggests that the people’s actual beliefs, as reflected in their decisions, do not conform to the rules of probability. The latter observation seems to favour normative option, but arguments can be made in support (or refutation) of either position.
The problem mentioned the previous paragraph is a perfect segue into the support interpretation, according to which the probability of an event occurring is the degree to which we should believe that it will occur (based on available evidence). This seems fine until we realize that evidence can come in many “shapes and sizes.” For example, compare the statements “the last time we did something similar we finished in 5 days, based on which we reckon there’s a 70-80% chance we’ll finish in 5 days” and “based on historical data for gathered for 50 projects, we believe that we have a 75% chance of finishing in 5 days. “ The two pieces of evidence offer very different levels of support. Therefore, although the support interpretation appears to be more objective than the belief interpretation, it isn’t actually so because it is difficult to determine which evidence one should use. So, unlike the case of subjective beliefs (where one only has to ask people about their personal odds), it is not straightforward to determine these probabilities empirically.
So we’re left with a situation in which we have three interpretations, each of which address specific aspects of probability but also have major shortcomings.
Is there any way to break the impasse?
A resolution?
Shafer suggests that the three interpretations of probability are best viewed as highlighting different aspects of a single situation: that of an idealized case where we have a sequence of experiments with known probabilities. Let’s see how this statement (which is essentially the frequency interpretation) can be related to the other two interpretations.
Consider my belief that that the task has a 75% chance of finishing in 5 days. This is analogous to saying that if the task is done several times over, I believe it would finish in 5 days in 75% of the cases. My belief can be objectively confirmed by testing my willingness to put up 75 cents to win a dollar if the task finishes in five days. Now, when I place this bet I have my (personal) reasons for doing so. However, these reasons ought to relate to knowledge of the fair odds involved in the said bet. Such fair odds can only be derived from knowledge of what would happen in a (possibly hypothetical) sequence of experiments.
The key assumption in the above argument is that my personal odds aren’t arbitrary – I should be able to justify them to another (rational) person.
Let’s look at the support interpretation. In this case I have hard evidence for stating that there’s a 75% chance of finishing in 5 days. I can take this hard evidence as my personal degree of belief (remember, as stated in the previous paragraph, any personal degree of belief should have some such rationale behind it.) However, since it is based on hard evidence, it should be rationally justifiable and hence can be associated with a sequence of experiments.
So what?
The main point from the above is the following: probabilities may be interpreted in different ways, but they have an underlying unity. That is, when we state that there is a 75% probability of finishing a task in 5 days, we are implying all the following statements (with no preference for any particular one):
- If we were to do the task several times over, it will finish within five days in three-fourths of the cases. Of course, this will hold only if the task is done a sufficiently large number of times (which may not be practical in most cases)
- We are willing to place a bet given 3:1 odds of completion within five days.
- We have some hard evidence to back up statement (1) and our betting belief (2).
In reality, however, we tend to latch on to one particular interpretation depending on the situation. One is unlikely to think in terms of hard evidence when one is buying a lottery ticket but hard evidence is a must when estimating a project. When tossing a coin one might instinctively use the frequency interpretation but when estimating a task that hasn’t been done before one might use personal belief. Nevertheless, it is worth remembering that regardless of the interpretation we choose, all three are implied. So the next time someone gives you a probabilistic estimate, ask them if they have the evidence to back it up for sure, but don’t forget to ask if they’d be willing to accept a bet based on their own stated odds. 🙂
Doing the right project is as important as doing the project right
Introduction
Many high profile projects fail because they succeed. This paradoxical statement is true because many projects are ill-conceived efforts directed at achieving goals that have little value or relevance to their host organisations. Project management focuses on ensuring that the project goals are achieved in an efficient manner. The goals themselves are often “handed down from above”, so the relevance or appropriateness of these is “out of scope” for the discipline of project management. Yet, the prevalence of projects of dubious value suggests that more attention needs to be paid to “front-end” decision making in projects – that is, decision making in the early stages, in which the initiative is just an idea. A paper by Terry Williams and Knut Samset entitled, Issues in front-end decision making on Projects looks at the problems associated with formulating the “right” project. This post is a summary and review of the paper.
What is the front-end phase of the project? According to Williams and Samset, “The front-end phase commences when the initial idea is conceived and proceeds to generate information, consolidate stakeholders’ views and positions, and arrive at the final decision as to whether or not to finance the project.”
Decisions made in the early stages of a project are usually more consequential than those made later on. Most major parameters – scope, funding, timelines etc. are more or less set in stone by the time a project is initiated. The problem is that these decisions are made at a time when the availability of relevant information is at its lowest. This highlights the role of sound judgement and estimation in decision making. Furthermore, these decisions may have long-term consequences for the organisation, so due care needs to be given to alignment of the project concept with the organisation’s strategic goals. Finally, as the cliché goes, the only constant is change: organisations exist in ever-changing environments, so projects need to have the right governance structures in place to help navigate through this turbulence. The paper is an exploration of some of these issues as they relate to front-end decision making in projects.
Defining the project concept
Williams and Samset define the terms concept as a mental construction that outlines how a problem will be solved or a need satisfied. Note that although the definition seems to imply that the term concept equates to technical approach, it is more than that. The project concept also includes considerations of the outcomes and their impact on the organisation and its environment.
The authors emphasise that organisations should to conceive several distinct concepts prior to initiating the project. To this end, they recommend having a clearly defined “concept definition phase” where the relevant stakeholders create and debate different concepts. Choosing the right concept is critical because it determines how the project will be carried out, what the end result is and how it affects the organisation. The authors emphasise that the concept should be determined on the basis of the required outcome rather than the current (undesirable) situation.
When success leads to failure
This is the point alluded to in the introduction: a project may produce the required outcomes, but still be considered a failure because the outcomes are not aligned with the organisation’s strategy. Such situations almost always arise because the project concept was not right. The authors describe an interesting example of such a project, which I’ll quote directly from the paper:
One such example is an onshore torpedo battery built inside the rocks on the northern coast of Norway in 2004 (Samset, 2008a). The facility was huge and complex, designed to accommodate as many as 150 military personnel for up to three months at a time. It was officially opened as planned and without cost overrun. It was closed down one week later by Parliamentary decision. Clearly, a potential enemy would not expose its ships to such an obvious risk: the concept had long since been overtaken by political, technological, and military development. What was quite remarkable was that this project, which can only be characterized as strategic failure, got little attention in the media, possibly because it was a success in tactical terms.
A brilliant example of a successful project that failed! The point, of course, is that although the strategic aspects of projects are considered to be outside the purview of project management, they must be given due consideration when the project is conceptualized. The result of a project must be effective for the organisation, the efficiency of project execution actually matters less.
Shooting straight – aligning the project to strategic goals
Aligning projects with strategic goals is a difficult because the organizational and social ramifications of a project are seldom clear at the start. This is because the problem may be inherently complex – for example, no one can foresee the implications of an organizational restructure (no, not even those expensive consultants who claim to be able to). Further, and perhaps more important, is the issue of social complexity: stakeholders have diverse, often irreconcilable, views on what needs to be done, let alone how it should be done. These two factors combine to make most organizational issues wicked problems.
Wicked problems have no straightforward solutions, so it is difficult if not impossible to ensure alignment to organizational strategy. There are several techniques that can be used to make sense of wicked problem. I’ve discussed one of these – dialogue mapping – in several prior posts. Paul Culmsee and I have elaborated on this and other techniques to manage wicked problems in our book, The Heretic’s Guide to Best Practices.
One has to also recognize that the process of alignment is messier still because politics and self interest play a role, particularly when the stakes are high. Further, at the individual level, decisions are never completely objective and are also subject to cognitive bias – which brings me to the next point…
Judgement and the formulation of organizational strategy
Formulating organizational strategy depends on making informed and accurate judgements about the future. Further, since strategies typically cover the mid to long term, one has to also allow some flexibility for adjustments along the way as one’s knowledge improves.
That’s all well and good, but it doesn’t take into account the fact that decision making isn’t a wholly rational process – humans who make the decisions are, at best, boundedly rational (sometimes rational, sometimes not). Bounded rationality manifests itself through cognitive biases – errors of perception that can lead us to making incorrect judgements. See my post on the role of cognitive bias in project failure for more on how these biases have affected high profile projects.
The scope for faulty decision making (via cognitive bias or any other mechanism) is magnified when one deals with wicked problems. There are a number of reasons for this including:
- Cause-effect relationships are often unclear.
- No one has complete understanding of the problem (the problem itself is often unclear).
- Social factors come into play (Is it possible make an “unbiased” decision about a proposed project that is going to affect one’s livelihood?)
- Consequent from points 1 through 3, stakeholders perceive the problem (and its solution) differently.
It is worth pointing out that project planning is generally “less wicked” than strategy formulation because the former involves more clear cut goals (even though they may be wrong-headed). There is more scope for wickedness in the latter because there are many more unknowns and “unknowables.”
Why estimates are incorrect
Cost is a major factor in deciding whether or not a project should go-ahead. Unfortunately, this is another front-end decision; one which needs to be made when there isn’t enough information available. In his book, Facts and Fallacies of Software Engineering, Robert Glass names poor estimation as one of the top causes of project failure. This is not to say that things haven’t improved. For example, Agile methods which advocate incremental/iterative development continually refine initial estimates based on actual, measurable progress.
Techniques such as reference class forecasting have been proposed to improve estimation for projects where incremental approaches are not possible (infrastructural projects, for example). However, this technique is subject to the reference class problem.
Finally, all the aforementioned techniques assume that reliable information on which estimates can be based is a) available and b) used correctly. But this is just where the problem lies: the two key factors that lead to poor estimation are a) the lack of knowledge about what exactly the work entails and b) the fact that people may misunderstand or even misrepresent the information if it is available.
Governance in an ever-changing environment
A negative consequence of the quest for organizational agility and flexibility is that organizational environments are turbulent. The main point of the paper is that traditional project management (as laid out in frameworks such as PMBOK) Is ill-suited to such environments. As they state:
The key point in this article, however, is that the environment in which most projects operate is complex and turbulent, and conventional project management is not well suited to such conditions, despite the attraction of project organization to companies in fast-moving environments seeking agility and responsiveness…
Yet, ironically, this uncertainty is the reason for the spectacular growth in adoption of project management methodologies (see this post for a discussion of a relevant case study).
For project management to be truly useful, it must be able to cope with and adapt to turbulent environments. To this end, it may be best to view project management as a set of activities that emerge from a real need rather than an arbitrary imposition dictated by methodologies that are divorced from reality. This is nothing new: iterative/incremental methods, which advocate adaptation of methods to suit the environment, are a step in this direction.
Adaptive methods are obviously easier to apply on smaller projects than larger ones. However, one could argue that the need for flexibility and adaptability is even greater on massive megaprojects than smaller ones. A major consequence of a changing environment is that people’s views on what needs to be done diverge. Recent work in applying dialogue mapping to large project environments shows that it is possible to reduce this divergence. Getting people on the “same page” is, I believe, the first step to successful governance, particular in unstable environments.
Lack of information
The most important decisions on projects have to be made upfront, when little or no reliable information is available. The authors argue that the lack of information can actually be a benefit in front-end decision for the following reasons:
- Too much information can lead to confusion and analysis paralysis.
- Information can get out of date quickly – forecasts based on outdated information can be worse than useless because they can mislead.
- It is often hard to tell between important and irrelevant information. The distinction may only become clear as the project proceeds.
Be that as it may, one cannot deny that front-end decision making is hampered by the lack of relevant information. The real problem, though, is that decisions are often made by those who cannot tell the difference between what’s important and what’s not.
Conclusion
The article is an excellent summary of the major impediments in front-end decision making on projects. Such decisions have a major impact on how the project unfolds, yet they are often made with little or no consideration of what exactly the project will do for the organisation, or what its impact will be.
In my experience, front-end decisions are invariably made in an ad-hoc manner, rooted more in hope and fantasy than reality. A first step to ensuring that organizations do the right project is to ensure that all stakeholders have a common understanding of the goals of the project – that is, what needs to be done. The next is to ensure a common understanding of how those goals will be achieved. Such stakeholder alignment is best achieved using communication-centric, collaborative techniques such as dialogue mapping. Only then, after ensuring that one is doing the right project, does it make sense to focus on doing the project right.
Trumped by conditionality: why many posts on this blog are not interesting
Introduction
A large number of the posts on this blog do not get much attention – not too many hits and few if any comments. There could be several reasons for this, but I need to consider the possibility that readers find many of the things I write about uninteresting. Now, this isn’t for the want of effort from my side: I put a fair bit of work into research and writing, so it is a little disappointing. However, I take heart from the possibility that it might not be entirely my fault: there’s a statistical reason (excuse?) for the dearth of quality posts on this blog. This (possibly uninteresting) post discusses this probabilistic excuse.
The argument I present uses the concepts of conditional probability and Bayes Theorem. Those unfamiliar with these may want to have a look at my post on Bayes theorem before proceeding further.
The argument
Grist for my blogging mill comes from a variety of sources: work, others’ stories, books, research papers and the Internet. Because of time constraints, I can write up only a fraction of the ideas that come to my attention. Let’s put a number to this fraction – say I can write up only 10% of the ideas I come across. Assuming that my intent is to write interesting stuff, this number corresponds to the best (or most interesting) ideas I encounter. Of course, the term “interesting” is subjective – an idea that fascinates me might not have the same effect on you. However this is a problem for most qualitative judgements, so we’ll accept this and move on.
If we denote the event “I have an interesting idea” by 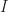
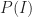

Then, if we denote the event “I have an idea that is uninteresting” by 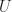
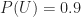
assuming that an idea must either be interesting or uninteresting (no other possibilities allowed).
Now, for me to write up an idea, I have to find it interesting (i.e. judge it as being in the top 10%). Let’s be generous and assume that I correctly recognise an interesting idea (as being interesting) 70% of the time. From this, the conditional probability of my writing a post given that I encounter an interesting idea, 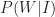
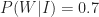
where 
On the flip side, let’s assume that I correctly recognise 80% of the uninteresting ideas that I encounter as being no good. This implies that I incorrectly identify 20% of the uninteresting stuff as being interesting. That is, 20% of the uninteresting stuff is wrongly identified as being blog-worthy. So, the conditional probability of my writing a post about an uninteresting idea, 

(If the above values for
Now, we want to figure out the probability that a post that appears on my blog is interesting – i.e. that a post is interesting given that I have written it up. Using the notation of conditional probability, this can be written as 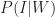
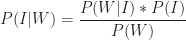
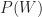
This can be written as,
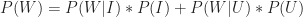
Substituting this in the expression for Bayes Theorem, we get:

Using the numbers quoted above

So, only 28% of the ideas I write about are interesting. The main reason for is my inability to filter out all the dross. These “false positives” – which are all the ideas that I identify as interesting but are actually not – are represented by the 
So, there you go: it isn’t my fault really. 🙂
I should point out that the percentage of interesting ideas written up will be small whenever the false positive term is significant compared to the numerator. In this sense the result is insensitive to the values of the probabilities that I’ve used.
Of course, the argument presented above is based on a number of assumptions. I assume that:
- Mostreaders of this blog share my interests.
- The ideas that I encounter are either interesting or uninteresting.
- There is an arbitrary cutoff point between interesting and uninteresting ideas (the 10% cutoff).
- There is an objective criterion for what’s interesting and what’s not, and that I can tell one from the other 70% of the time.
- The relevant probabilities are known.
…and so, to conclude
I have to accept that much of the stuff I write about will be uninteresting, but can take consolation in the possibility that it is a consequence of conditional probabilities. I’m trumped by conditionality, once more.
Acknowledgements
This post was inspired by Peter Rousseeuw’s brilliant and entertaining paper entitled, Why the Wrong Papers Get Published. Thanks also go out to Vlado Bokan for interesting conversations about conditional probabilities and Bayes theorem.


