Archive for the ‘Enterprise Architecture’ Category
TOGAF or not TOGAF… but is that the question?
“The ‘Holy Grail’ of effective collaboration is creating shared understanding, which is a precursor to shared commitment.” – Jeff Conklin.
“Without context, words and actions have no meaning at all.” – Gregory Bateson.
I spent much of last week attending a class on the TOGAF Enterprise Architecture (EA) framework. Prior experience with IT frameworks such as PMBOK and ITIL had taught me that much depends on the instructor – a good one can make the material come alive whereas a not-so-good one can make it an experience akin to watching grass grow. I needn’t have worried: the instructor was superb, and my classmates, all of whom are experienced IT professionals / architects, livened up the proceedings through comments and discussions both in class and outside it. All in all, it was a thoroughly enjoyable and educative experience, something I cannot say for many of the professional courses I have attended.
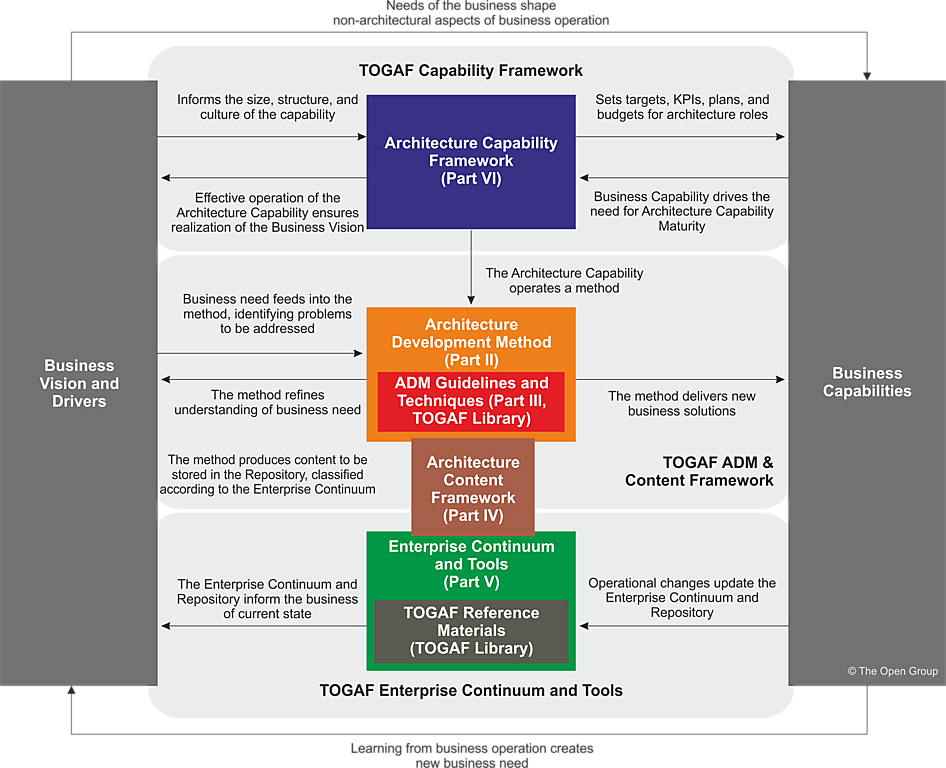
One of the things about that struck me about TOGAF is the way in which the components of the framework hang together to make a coherent whole (see the introductory chapter of the framework for an overview). To be sure, there is a lot of detail within those components, but there is a certain abstract elegance – dare I say, beauty – to the framework.
That said TOGAF is (almost) entirely silent on the following question which I addressed in a post late last year:
Why is Enterprise Architecture so hard to get right?
Many answers have been offered. Here are some, extracted from articles published by IT vendors and consultancies:
- Lack of sponsorship
- Not engaging the business
- Inadequate communication
- Insensitivity to culture / policing mentality
- Clinging to a particular tool or framework
- Building an ivory tower
- Wrong choice of architect
(Note: the above points are taken from this article and this one)
It is interesting that the first four issues listed are related to the fact that different stakeholders in an organization have vastly different perspectives on what an enterprise architecture initiative should achieve. This lack of shared understanding is what makes enterprise architecture a socially complex problem rather than a technically difficult one. As Jeff Conklin points out in this article, problems that are technically complex will usually have a solution that will be acceptable to all stakeholders, whereas socially complex problems will not. Sending a spacecraft to Mars is an example of the former whereas an organization-wide ERP (or EA!) project or (on a global scale) climate change are instances of the latter.
Interestingly, even the fifth and sixth points in the list above – framework dogma and retreating to an ivory tower – are usually consequences of the inability to manage social complexity. Indeed, that is precisely the point made in the final item in the list: enterprise architects are usually selected for their technical skills rather than their ability to deal with ambiguities that are characteristic of social complexity.
TOGAF offers enterprise architects a wealth of tools to manage technical complexity. These need to be complemented by a suite of techniques to reconcile worldviews of different stakeholder groups. Some examples of such techniques are Soft Systems Methodology, Polarity Management, and Dialogue Mapping. I won’t go into details of these here, but if you’re interested, please have a look at my posts entitled, The Approach – a dialogue mapping story and The dilemmas of enterprise IT for brief introductions to the latter two techniques via IT-based examples.
<Advertisement > Better yet, you could check out Chapter 9 of my book for a crash course on Soft Systems Methodology and Polarity Management and Dialogue Mapping, and the chapters thereafter for a deep dive into Dialogue Mapping </Advertisement>.
Apart from social complexity, there is the problem of context – the circumstances that shape the unique culture and features of an organization. As I mentioned in my introductory remarks, the framework is abstract – it applies to an ideal organization in which things can be done by the book. But such an organization does not exist! Aside from unique people-related and political issues, all organisations have their own quirks and unique features that distinguish them from other organisations, even within the same domain. Despite superficial resemblances, no two pharmaceutical companies are alike. Indeed, the differences are the whole point because they are what make a particular organization what it is. To paraphrase the words of the anthropologist, Gregory Bateson, the differences are what make a difference.
Some may argue that the framework acknowledges this and encourages, even exhorts, people to tailor the framework to their needs. Sure, the word “tailor” and its variants appear almost 700 times in the version 9.1 of the standard but, once again, there is no advice offered on how this tailoring should be done. And one can well understand why: it is impossible to offer any sensible advice if one doesn’t know the specifics of the organization, which includes its context.
On a related note, the TOGAF framework acknowledges that there is a hierarchy of architectures ranging from the general (foundation) to the specific (organization). However despite the acknowledgement of diversity, in practice TOGAF tends to focus on similarities between organisations. Most of the prescribed building blocks and processes are based on assumed commonalities between the structures and processes in different organisations. My point is that, although similarities are important, architects need to focus on differences. These could be differences between the organization they are working in and the TOGAF ideal, or even between their current organization and others that they have worked with in the past (and this is where experience comes in really handy). Cataloguing and understanding these unique features – the differences that make a difference – draws attention to precisely those issues that can cause heartburn and sleepless nights later.
I have often heard arguments along the lines of “80% of what we do follows a standard process, so it should be easy for us to standardize on a framework.” These are famous last words, because some of the 20% that is different is what makes your organization unique, and is therefore worthy of attention. You might as well accept this upfront so that you get a realistic picture of the challenges early in the game.
To sum up, frameworks like TOGAF are abstractions based on an ideal organization; they gloss over social complexity and the unique context of individual organisations. So, questions such as the one posed in the title of this post are akin to the pseudo-choice between Coke and Pepsi, for the real issue is something else altogether. As Tom Graves tells us in his wonderful blog and book, the enterprise is a story rather than a structure, and its architecture an ongoing sociotechnical drama.
Beyond entities and relationships – towards an emergent approach to data modelling
Introduction – some truths about data modelling
It has been said that data is the lifeblood of business. The aptness of this metaphor became apparent to when I was engaged in a data mapping project some years ago. The objective of that effort was to document all the data flows within the organization. The final map showed very clearly that the volume of data on the move was good indicator of the activity of the function: the greater the volume, the more active the function. This is akin to the case of the human body wherein organs that expend the more energy tend to have a richer network of blood vessels.
Although the above analogy is far from perfect, it serves to highlight the simple fact that most business activities involve the movement and /or processing of data. Indeed, the key function of information systems that support business activities is to operate on and transfer data. It therefore matters a lot as to how data is represented and stored. This is the main concern of the discipline of data modelling.
The mainstream approach to data modelling assumes that real world objects and relationships can be accurately represented by models. As an example, a data model representing a sales process might consist of entities such as customers and products and their relationships, such as sales (customer X purchases product Y). It is tacitly assumed that objective, bias-free models of entities and relationships of interest can be built by asking the right questions and using appropriate information collection techniques.
However, things are not quite so straightforward: as professional data modellers know, real-world data models are invariably tainted by compromises between rigour and reality. This is inevitable because the process of building a data model involves at least two different sets of stakeholders whose interests are often at odds – namely, business users and data modelling professionals. The former are less interested in the purity of model than the business process that it is intended to support; the interests of the latter, however, are often the opposite.
This reveals a truth about data modelling that is not fully appreciated by practitioners: that it is a process of negotiation rather than a search for a true representation of business reality. In other words, it is a socio-technical problem that has wicked elements. As such then, data modelling ought to be based on the principles of emergent design. In this post I explore this idea drawing on a brilliant paper by Heinz Klein and Kalle Lyytinen entitled, Towards a New Understanding of Data Modelling as well as my own thoughts on the subject.
Background
Klein and Lyytinen begin their paper by asking four questions that are aimed at uncovering the tacit assumptions underlying the different approaches to data modelling. The questions are:
- What is being modelled? This question delves into the nature of the “universe” that a data model is intended to represent.
- How well is the result represented? This question asks if the language, notations and symbols used to represent the results are fit for purpose – i.e. whether the language and constructs used are capable of modelling the domain.
- Is the result valid? This asks the question as to whether the model is a correct representation of the domain that is being modelled.
- What is the social context in which the discipline operates? This question is aimed at eliciting the views of different stakeholders regarding the model: how they will use it, whether their interests are taken into account and whether they benefit or lose from it.
It should be noted that these questions are general in that they can be used to enquire into any discipline. In the next section we use these questions to uncover the tacit assumptions underlying the mainstream view of data modelling. Following that, we propose an alternate set of assumptions that address a major gap in the mainstream view.
Deconstructing the mainstream view
What is being modelled?
As Klein and Lyytinen put it, the mainstream approach to data modelling assumes that the world is given and made up of concrete objects which have natural properties and are associated with [related to] other objects. This assumption is rooted in a belief that it is possible to build an objectively true picture of the world around us. This is pretty much how truth is perceived in data modelling: data/information is true or valid if it describes something – a customer, an order or whatever – as it actually is.
In philosophy, such a belief is formalized in the correspondence theory of truth, a term that refers to a family of theories that trace their origins back to antiquity. According to Wikipedia:
Correspondence theories claim that true beliefs and true statements correspond to the actual state of affairs. This type of theory attempts to posit a relationship between thoughts or statements on one hand, and things or facts on the other. It is a traditional model which goes back at least to some of the classical Greek philosophers such as Socrates, Plato, and Aristotle. This class of theories holds that the truth or the falsity of a representation is determined solely by how it relates to a reality; that is, by whether it accurately describes that reality.
In short: the mainstream view of data modelling is based on the belief that the things being modelled have an objective existence.
How well is the result represented?
If data models are to represent reality (as it actually is), then one also needs an appropriate means to express that reality in its entirety. In other words, data models must be complete and consistent in that they represent the entire domain and do not contain any contradictory elements. Although this level of completeness and logical rigour is impossible in practice, much research effort is expended in finding evermore complete and logical consistent notations.
Practitioners have little patience with cumbersome notations invented by theorists, so it is no surprise that the most popular modelling notation is the simplest one: the entity-relationship (ER) approach which was first proposed by Peter Chen. The ER approach assumes that the world can be represented by entities (such as customer) with attributes (such as name), and that entities can be related to each other (for example, a customer might be located at an address – here “is located at” is a relationship between the customer and address entities). Most commercial data modelling tools support this notation (and its extensions) in one form or another.
To summarise: despite the fact that the most widely used modelling notation is not based on rigorous theory, practitioners generally assume that the ER notation is an appropriate vehicle to represent what is going on in the domain of interest.
Is the result valid?
As argued above, the mainstream approach to data modelling assumes that the world of interest has an objective existence and can be represented by a simple notation that depicts entities of interest and the relationships between them. This leads to the question of the validity of the models thus built. To answer this we have to understand how data models are constructed.
The process of model-building involves observation, information gathering and analysis – that is, it is akin to the approach used in scientific enquiry. A great deal of attention is paid to model verification, and this is usually done via interaction with subject matter experts, users and business analysts. To be sure, the initial model is generally incomplete, but it is assumed that it can be iteratively refined to incorporate newly surfaced facts and fix errors. The underlying belief is that such a process gets ever-closer to the truth.
In short: it is assumed that it an ER model built using a systematic and iterative process of enquiry will result in a model that is a valid representation of the domain of interest.
What is the social context in which the discipline operates?
From the above, one might get the impression that data modelling involves a lot of user interaction. Although this is generally true, it is important to note that the users’ roles are restricted to providing information to data modellers. The modellers then interpret the information provided by users and cast into a model.
This brings up an important socio-political implication of the mainstream approach: data models generally support business applications that are aimed at maintaining and enhancing managerial control through automation and / or improved oversight. Underlying this is the belief that a properly constructed data model (i.e. one that accurately represents reality) can enhance business efficiency and effectiveness within the domain represented by the model.
In brief: data models are built to further the interests of specific stakeholder groups within an organization.
Summarising the mainstream view
The detailed responses to the questions above reveal that the discipline of data modelling is based on the following assumptions:
- The domain of interest has an objective existence.
- The domain can be represented using a (more or less) logical language.
- The language can represent the domain of interest accurately.
- The resulting model is based largely on a philosophy of managerial control, and can be used to drive organizational efficiency and effectiveness.
Many (most?) professional data management professionals will see these assumptions as being uncontroversial. However, as we shall see next, things are not quite so simple…
Motivating an alternate view of data modelling
In an earlier section I mentioned the correspondence theory of truth which tells us that true statements are those that correspond to the actual state of affairs in the real world. A problem with correspondence theories is that they assume that: a) there is an objective reality, and b) that it is perceived in the same way by everyone. This assumption is problematic, especially for issues that have a social dimension. Such issues are perceived differently by different stakeholders, each of who will seek data that supports their point of view. The problem is that there is no way to determine which data is “objectively right.” More to the point, in such situations the very notion of “objective rightness” can be legitimately questioned.
Another issue with correspondence theories is that a piece of data can at best be an abstraction of a real-world object or event. This is a serious problem with correspondence theories in the context of business intelligence. For example, when a sales rep records a customer call, he or she notes down only what is required by the CRM system. Other data that may well be more important is not captured or is relegated to a “Notes” or “Comments” field that is rarely if ever searched or accessed.
Another perspective on truth is offered by the so called consensus theory which asserts that true statement are those that are agreed to by the relevant group of people. This is often the way “truth” is established in organisations. For example, managers may choose to calculate KPIs using certain pieces of data that are deemed to be true. The problem with this is that consensus can be achieved by means that are not necessarily democratic .For example, a KPI definition chosen by a manager may be contested by an employee. Nevertheless, the employee has to accept it because organisations are not democracies. A more significant issue is that the notion of “relevant group” is problematic because there is no clear criterion by which to define relevance. Quite naturally this leads to conflict and ill-will.
This conclusion leads one to formulate alternative answers to four questions posed above, thus paving the way to a new approach to data modelling.
An alternate view of data management
What is being modelled?
The discussion of the previous section suggests that data models cannot represent an objective reality because there is never any guarantee that all interested parties will agree on what that reality is. Indeed, insofar as data models are concerned, it is more useful to view reality as being socially constructed – i.e. collectively built by all those who have a stake in it.
How is reality socially constructed? Basically it is through a process of communication in which individuals discuss their own viewpoints and agree on how differences (if any) can be reconciled. The authors note that:
…the design of an information system is not a question of fitness for an organizational reality that can be modelled beforehand, but a question of fitness for use in the construction of a [collective] organizational reality…
This is more in line with the consensus theory of truth than the correspondence theory.
In brief: the reality that data models are required to represent is socially constructed.
How well is the result represented?
Given the above, it is clear that any data model ought to be subjected to validation by all stakeholders so that they can check that it actually does represent their viewpoint. This can be difficult to achieve because most stakeholders do not have the time or inclination to validate data models in detail.
In view of the above, it is clear that the ER notation and others of its ilk can represent a truth rather than the truth – that is, they are capable of representing the world according to a particular set of stakeholders (managers or users, for example). Indeed, a data model (in whatever notation) can be thought of one possible representation of a domain. The point is, there are as many representations possible as there are stakeholder groups and in mainstream data modelling, and one of these representations “wins” while the others are completely ignored. Indeed, the alternate views generally remain undocumented so they are invariably forgotten. This suggests that a key step in data modelling would be to capture all possible viewpoints on the domain of interest in a way that makes a sensible comparison possible. Apart from helping the group reach a consensus, such documentation is invaluable to explain to future users and designers why the data model is the way it is. Regular readers of this blog will no doubt see that the IBIS notation and dialogue mapping could be hugely helpful in this process. It would take me too far afield to explore this point here, but I will do so in a future post.
In brief: notations used by mainstream data modellers cannot capture multiple worldviews in a systematic and useful way. These conventional data modelling languages need to be augmented by notations that are capable of incorporating diverse viewpoints.
Is the result valid?
The above discussion begs a question, though: what if two stakeholders disagree on a particular point?
One answer to this lies in Juergen Habermas’ theory of communicative rationaility that I have discussed in detail in this post. I’ll explain the basic idea via the following excerpt from that post:
When we participate in discussions we want our views to be taken seriously. Consequently, we present our views through statements that we hope others will see as being rational – i.e. based on sound premises and logical thought. One presumes that when someone makes claim, he or she is willing to present arguments that will convince others of the reasonableness of the claim. Others will judge the claim based the validity of the statements claimant makes. When the validity claims are contested, debate ensues with the aim of getting to some kind of agreement.
The philosophy underlying such a process of discourse (which is simply another word for “debate” or “dialogue”) is described in the theory of communicative rationality proposed by the German philosopher Jurgen Habermas. The basic premise of communicative rationality is that rationality (or reason) is tied to social interactions and dialogue. In other words, the exercise of reason can occur only through dialogue. Such communication, or mutual deliberation, ought to result in a general agreement about the issues under discussion. Only once such agreement is achieved can there be a consensus on actions that need to be taken. Habermas refers to the latter as communicative action, i.e. action resulting from collective deliberation…
In brief: validity is not an objective matter but a subjective – or rather an intersubjective one that is, validity has to be agreed between all parties affected by the claim.
What is the social context in which the discipline operates?
From the above it should be clear that the alternate view of data management is radically different from the mainstream approach. The difference is particularly apparent when one looks at the way in which the alternate approach views different stakeholder groups. Recall that in the mainstream view, managerial perspectives take precedence over all others because the overriding aim of data modelling (as indeed most enterprise IT activities) is control. Yes, I am aware that it is supposed to be about enablement, but the question is enablement for whom? In most cases, the answer is that it enables managers to control. In contrast, from the above we see that the reality depicted in a data (or any other) model is socially constructed – that is, it is based on a consensus arising from debates on the spectrum of views that people hold. Moreover, no claim has precedence over others on virtue of authority. Different interpretations of the world have to be fused together in order to build a consensually accepted world.
The social aspect is further muddied by conflicts between managers on matters of data ownership, interpretation and access. Typically, however, such matters lie outside the purview of data modellers
In brief: the social context in which the discipline operates is that there are a wide variety of stakeholder groups, each of which may hold different views. These must be debated and reconciled.
Summarising the alternate view
The detailed responses to the questions above reveal that the alternate view of data modelling is based on the following assumptions:
- The domain of interest is socially constructed.
- The standard representations of data models are inadequate because they cannot represent multiple viewpoints. They can (and should) be supplemented by notations that can document multiple viewpoints.
- A valid data model is constructed through an iterative synthesis of multiple viewpoints.
- The resulting model is based on a shared understanding of the socially constructed domain.
Clearly these assumptions are diametrically opposed to those in the mainstream. Let’s briefly discuss their implications for the profession
Discussion
The most important implication of the alternate view is that a data model is but one interpretation of reality. As such, there are many possible interpretations of reality and the “correctness” of any particular model hinges not on some objective truth but on an agreed, best-for-group interpretation. A consequence of the above is that well-constructed data models “fuse” or “bring together” at least two different interpretations – those of users and modellers. Typically there are many different groups of users, each with their own interpretation. This being the case, it is clear that the onus lies on modellers to reconcile any differences between these groups as they are the ones responsible for creating models.
A further implication of the above is that it is impossible to build a consistent enterprise-wide data model. That said, it is possible to have a high-level strategic data model that consists, say, of entities but lacks detailed attribute-level information. Such a model can be useful because it provides a starting point for a dialogue between user groups and also serves to remind modellers of the entities they may need to consider when building a detailed data model.
The mainstream view asserts that data is gathered to establish the truth. The alternate view, however, makes us aware that data models are built in such a way as to support particular agendas. Moreover, since the people who use the data are not those who collect or record it, a gap between assumed and actual meaning is inevitable. Once again this emphasises that fact that the meaning of a particular piece of data is very much in the eye of the beholder.
In closing
The mainstream approach to data modelling reflects the general belief that the methods of natural sciences can be successfully applied in the area of systems development. Although this is a good assumption for theoretical computer science, which deals with constructs such as data structures and algorithms, it is highly questionable when it comes to systems development in large organisations. In the latter case social factors dominate, and these tend to escape any logical system. This simple fact remains under-appreciated by the data modelling community and, for that matter, much of the universe of corporate IT.
The alternate view described in this post draws attention to the social and political aspects of data modelling. Although IT vendors and executives tend to give these issues short shrift, the chronically high failure rate of data-centric initiatives (such as those aimed at building enterprise data warehouses) warns us to pause and think. If there is anything at all to be learnt from these failures, it is that data modelling is not a science that deals with facts and models, but an art that has more to do with negotiation and law-making.
An introduction to emergent design
Note: For an updated piece on emergent design please see: https://eight2late.wordpress.com/2023/05/24/what-is-emergent-design/
Introduction
Over the last few months, I’ve published a number of posts in which the term emergent design makes a cameo appearance (see this article or this interview for example). Some readers may have noticed that although the term is used in various contexts in the articles/interviews, it is not explicitly defined anywhere. This is deliberate. Emergent design is…well, emergent, so a detailed definition is neither necessary nor useful – providing one can describe a set of guidelines for its practice. My main aim in this post is to do just that. To keep things concrete I will discuss the guidelines in the context of technical initiatives in organisations.
(Note: Before going any further a couple of clarifications are in order. Firstly, the word emergent as used here has nothing to do with emergence in complex systems. Secondly, the guidelines provided here are a starting point, not a comprehensive list.)
The wickedness of technology
Most technical initiatives in large organisations are planned, designed and executed in a top-down manner, with little or no attempt to understand the existing culture and / or on-the-ground realities. This observation applies not only to enterprise software projects, such as those involving Collaboration or Customer Relationship Management platforms, but also to the establishment of new functions such as building a data science capability.
Top down approaches are liable to fail because technical initiatives display many of the characteristics of wicked problems. In particular, they are:
- Are one-shot operations – for example, an ERP system is simply too expensive to implement over and over again.
- Have no stopping rule – technical systems are never completely done; there are always things to be fixed and additional features to be implemented.
- Are highly contentious – whether or not an initiative is good, or even necessary, depends on who you ask.
- Could be done in other, possibly “better”, ways – and the problem is that one person’s “better” is another one’s “worse”!
- Are essentially unique – and don’t let vendors or Big $$$ consultants tell you otherwise!
These characteristics make technical problems socially complex – that is, different stakeholder groups have different perceptions of the problem that the initiative is intended to address. The most important implication of social complexity is that it cannot be tackled using rational methods of planning, design and implementation that are taught in schools, propagated in books, or evangelized by standards authorities and assorted snake oil salespersons. For these reasons, it is more accurate to refer to such problems as sociotechnical problems.
Enter emergent design
The term emergent design was coined by David Cavallo in the context of technology-driven education reforms in indigenous cultures (the original paper by David Cavallo can be accessed here). Cavallo observed that traditional systems engineering approaches that attempt to change an educational system in a top-down manner fail primarily because they do not take into account the unique features of local cultures. Instead, he found that using the existing culture as a starting point from which to work towards systemic change offered a much better chance of the new ways taking root. In his words, “[the] adoption and implementation of new methodologies needs to be based in, and grow from, the existing culture.”
Cavallo’s words hold the key to applying emergent design in the context of sociotechnical initiatives: it is to take the concerns of those affected by the initiatives seriously.
“Ah, so it’s like Agile software development,” concludes the Agilista.
Not quite. As I will discuss in the remainder of this post, although emergent design shares a few number features with Agile methods, there’s considerably more to it than that. That said, chances are that good Agile coaches are emergent design practitioners without knowing it. This is something that will become apparent as we go on.
Guidelines for emergent design
I have, for a while, been thinking about what emergent design means in the context of sociotechnical initiatives in organisations. Among other things, I have been looking at how it might be applied to a wide variety initiatives that are traditionally planned upfront – things such as offshoring and enterprise-wide projects such as data warehouse or enterprise resource planning initiatives.
In one of those serendipitous occurrences, last week I happened re-read an old series of articles entitled Confessions of a post-SharePoint Architect written by my friend, the ace sensemaker and emergent entrepreneur, Paul Culmsee. Although the series focuses on emergent design principles in the context of the Microsoft SharePoint platform, many of the points that Paul makes apply to sociotechnical initiatives in general. In addition to material drawn from Paul’s blog, I also borrow from a few posts on my blog. In the interests of space I have provided only a brief overview of the points because they have been elaborated elsewhere. The original pieces fill in a lot of relevant detail, so please do follow the links if you have the inclination and the time.
With that said, let’s get to it.
Be a midwife rather than an expert
In a paper entitled, On the planning crisis, Horst Rittel (the man who coined the term wicked problem) wrote:
You do not learn in school how to deal with wicked problems…expertise and ignorance is distributed over all participants in a wicked problem. There is a symmetry of ignorance among those who participate because nobody knows better by virtue of his degrees or his status. There are no experts (which is irritating for experts), and if experts there are, they are only experts in guiding the process of dealing with a wicked problem, but not for the subject matter of the problem.
The first guideline of emergent design is to realize that no one is an expert – not you nor your Big $$$ consultant. The only way to build a robust and lasting system or process is for everyone to put their heads together and work towards it in a collaborative fashion, dispensing with the pretence that one can outsource one’s thinking to the “expert”. Indeed, the role of the “expert” is to create and foster the conditions for such collaboration to occur. Paul and I elaborate on this point at length in our book and this paper (summarized in this post).
In brief, the knowledge required to successfully implement a sociotechnical initiative is distributed across all stakeholders (analysts, consultants, architects and, above all, users). Pulling all this together into a coherent whole has more to do with facilitation and people skills than technology.
Ensure that governance is about enablement rather than control
Most organisations have onerous procedures to ensure that people do the right thing. I submit that many of these encourage a checkbox-based compliance mentality aimed at ensuring that people comply in letter, but not necessarily in spirit (actually, never in spirit). As Paul mentions in this post governance ought to be about enablement rather than compliance or control.
There’s a very simple test to tell one from the other: when you come across a procedure such as an SOP or a methodology that you are required to follow, ask yourself this question: does this help me do my job?
If the answer positive, the procedure is an enabler; if not, it is likely a control that is primarily intended as a CYA mechanism.
Do not penalize people for learning
The main rationale behind iterative and incremental approaches to technical projects is that they encourage (and take advantage) of continuous learning. Incremental increases in functionality are easier to test exhaustively and errors are also easier to correct. Reviews and retrospectives also tend to be more focused leading to a better chance of lessons actually being learnt. Thanks to the Agile movement, this is now well known and understood in the world of tech.
However, learning is not just a matter of using iterative/incremental methodologies; one also needs to build an environment that encourages it. This is trickier matter because it depends on things that are outside an individual manager’s control; indeed it has more to do with the entire function or even the organization. In an organisation with a strong blame culture, the culture tends to win against pretty much any methodology, agile or otherwise. Blame cultures preclude learning because mistakes are punished and people are scapegoated as a result. Check out this article on learning organizations for more on this topic, and this post for a more nuanced (realistic?) view.
With that said for the importance of learning, it is also important to note that there are some situations where learning is less important. This is the case for work for that can be planned and scripted in detail up front. It is important to be able to distinguish between the two types of situations…which brings us to the next point.
Understand the difference between complicated and complex initiatives
Requirements analysis is one of the first activities in traditional system development. Most technical initiatives that are driven by a vendor or consultant will have many sessions for this at the front-end of an engagement. Enterprise wisdom tells us that things need to be specified in detail at the start. The rationale behind this is to set requirements in stone so that the entire project can be planned in detail before actual implementation begins. Such an approach is fine if one knows for sure:
- How the future is going to unfold and has appropriate contingencies in place for adverse events;
- That users have a clear idea of what they want, and
- That requirements will not change (or will change minimally).
It is obvious that this approach will be disastrous if any of the above assumptions are incorrect. Unfortunately it is more often the case that the assumptions do not hold for sociotechnical initiatives.
So how does one distinguish between initiatives that can be planned in detail upfront and those that can’t?
The distinction is best illustrated via an example: consider a project to replace a fixed line phone system by VoIP versus an initiative to set up a data science function. The first project has a fixed set of requirements across different groups. The second one, in contrast, involves diverse stakeholder groups, each with their own unique expectations of the system. Both projects are complicated from the technology point of view, but the second one has elements of wickedness arising from social complexity. Consequently, the two projects cannot be run in the same way. In particular, the first one can be planned in detail upfront while the second one cannot. Borrowing from David Snowden’s Cynefin framework, we call the first type of project complicated and the second one complex. You need to understand which kind of initiative you are dealing with before deciding which approach would be appropriate.
Beware of platitudinous goals
The technology marketplace is one that is largely buzzword driven. An in-vogue buzzwords at the time this piece was written is AI. Buzzwords, while sounding “right”, are actually platitudes – words that are devoid of meaning because different people interpret and use them differently. The use of platitudes, therefore, results in confusion rather than clarity. For example, does it mean (in the context of an organisation) to “implement AI”?
People tend to use platitudes as mental shortcuts to avoid thinking things through and coming up with their own opinions. It is therefore pointless to ask a person who uses a platitude to clarify what he or she means: they have not thought it through and will therefore be unable to give you a good answer.
The best way to deconstruct a platitude is via an oblique approach that is best illustrated through an example.
Say someone tells you that they want to implement AI. Asking them to define AI is not a good way to go because the answer you get is likely to be couched in further platitudes such as higher automation and insight. Instead, it is better to ask them what difference would be apparent if AI were to be implemented. To answer this question, they would have to come down from platitude-land and start thinking about concrete, measurable outcomes.
Use open questions to broaden perspectives
A more general point to note from the foregoing is that the framing of questions matters, particularly when one wants people to come up with ideas. For example, instead of asking people what they like (or dislike) about a particular approach, it is generally better to ask them what aspects of the approach are important to them. The latter question is neutrally framed so it does not impose any constraints on their thinking
Another good way to get people thinking about possibilities is to ask them what they would like to do if there were no constraints (such as budget or time, say). Conversely, if you encounter a constraining factor (like a company policy), it is sometimes helpful to ask what the intent behind the policy is.
If posed in the right way and in the right environment, answers to such questions get people to think beyond their immediate concerns and focus on purposes and outcomes instead.
Check out Paul’s posts on powerful questions to find out more about these perspective-expanding questions.
Understand the need for different types of thinking
One of the ironies of sociotechnical initiatives is that the most important decisions have to be made when the information available is the least. As I wrote in the introduction to this paper,
The early stages of projects are fraught with ambiguity. Yet, it is at this “front end” of projects that the most important decisions have to be made. Front-end decisions are hard because there is:
- uncertainty about scope, i.e. about what needs to be done;
- uncertainty about rationale, i.e. why it needs to be done; and
- uncertainty about approach, i.e. how it should be done.
Arguably, the lack of clarity regarding any of these can sow the seeds of failure in the early stages of a project.
The standard approach is to treat uncertainty as a problem that can be solved through convergent thinking – i.e. the kind of thinking that assumes a problem has a single “correct answer.” However, the uncertainty associated with sociotechnical projects has a social dimension; different people have different perceptions of things like scope and rationale, as well as different coping mechanisms for ambiguity. Thus sociotechnical uncertainty is a wicked problem that has no single “right answer.” This can cause anxiety for some. One therefore needs to begin with divergent thinking, which is largely about generating ideas and options and move to convergent thinking only when:
- The group has a shared understanding of the main issues.
- An adequate set of options have been generated.
As I alluded to above, people tend to show a preference for one type of thinking over the other. The strength of collaborative problem solving lies precisely in the fact that a group is likely to have a mix of the two types of thinkers.
It is perhaps obvious, but still worth mentioning that the other standard way to deal with uncertainty is to impose a solution by diktat or governance. Clearly such approaches are doomed to fail because they suppress the problem instead of solving it.
Consider long term consequences
It is an unfortunate fact of life that cost tends to be the ultimate arbiter on organisational decisions. Vendors know this, and take advantage of it when crafting their proposals. The contract goes to the lowest bidder and the rest, as they say, is tragedy. Although cost is an important criterion in technical decisions, making it the overriding concern is a recipe for future disappointment.
The general lesson to draw from this is that one must consider the longer-term consequences of one’s choices. This can be hard to do because the distant future is less salient than the present or the immediate future. A good way to look beyond immediate concerns (such as cost) is to use the solution after next principle proposed by Gerald Nadler and Shozo Hibino in their book, Breakthrough Thinking. The basic idea behind the principle is to get people to focus on the goals that lie beyond the immediate goal. The process of thinking about and articulating longer-term goals can often provide insights into potential problems with the current goals and/or how they are being achieved.
Build in spare capacity
In his book on antifragility, Nicholas Taleb points out that the opposite of fragility is not robustness or resilience, rather it is the ability to thrive on or benefit from uncertainty. There is no word in the English language to describe such behavior, and that is what led him to coin the term antifragile.
In a post inspired by the book, I outlined the elements of an antifragile IT strategy. One of the key points of such a strategy is the assumption that, despite our best laid plans, it is inevitable that something important will have been overlooked. It is therefore important to build in some spare capacity to deal with the unexpected events and demands.
Design so as to increase your future choices
This is perhaps the most important point in my list because it encapsulates all the other points. I have adapted it from Heinz von Foerster’s ethical imperative which states that one should always act so as to increase the number of choices in the future. This principle is useful as a tiebreaker between two designs that are close in all other respects. However, there is more to it than just that. I have found it particularly useful in making decisions that have wider, social consequences beyond technology. There is very little critical scrutiny of the benefits of these as claimed by vendors and advisories. This principle can help you see through the fog of marketing rhetoric and advisory hype.
Parting thoughts
One of the paradoxes of life is that the harder we strive for something – money, happiness or whatever – the more unattainable it seems to become. Indeed, some of the most financially successful people (Bill Gates and Warren Buffett, for example) became rich by doing what they loved. Their financial success was a happy byproduct of their engagement in their work. The economist John Kay formalized this paradoxical notion in his concept of obliquity – that certain goals are best attained via indirect means.
If you have been patient enough to read through this piece, you will have noted that some of the guidelines listed above have a hint of obliquity about them. This is no surprise; indeed it is inevitable in a design approach that values people over processes and improvisation (or even serendipity) over planning.
I usually conclude my posts with a summary of the main message. For reasons that should be obvious I will not do that here. Instead, I will end by pointing out yet another feature of emergent design that you have likely figured out already: the guidelines listed above are actually domain neutral; they can be applied to pretty much any area of endeavour. This is no surprise: wicked problems aren’t domain specific and therefore neither are the techniques to deal with them. For example, see my interview with Neil Preston for a perspective on emergent design in organizational change and my book co-authored with Paul for ways in which it can be applied to domains as diverse as town planning and knowledge management.
…and now I really must stop for I have gone on too long. Many thanks for your patience!
Acknowledgement
My thanks go out to Paul Culmsee for his feedback on a draft version of this post.



{kind=link}