Archive for the ‘Estimation’ Category
An introduction to Monte Carlo simulation of project tasks
Introduction
In an essay on the uncertainty of project task estimates, I described how a task estimate corresponds to a probability distribution. Put simply, a task estimate is actually a range of possible completion times, each with a probability of occurrence specified by a distribution. If one knows the distribution, it is possible to answer questions such as: “What is the probability that the task will be completed within x days?”
The reliability of such predictions depends on how faithfully the distribution captures the actual spread of task durations – and therein lie at least a couple of problems. First, the probability distributions for task durations are generally hard to characterise because of the lack of reliable data (estimators are not very good at estimating, and historical data is usually not available). Second, many realistic distributions have complicated mathematical forms which can be hard to characterise and manipulate.
These problems are compounded by the fact that projects consist of several tasks, each one with its own duration estimate and (possibly complicated) distribution. The first issue is usually addressed by fitting distributions to point estimates (such as optimistic, pessimistic and most likely times as in PERT) and then refining these estimates and distributions as one gains experience. The second issue can be tackled by Monte Carlo techniques, which involve simulating the task a number of times (using an appropriate distribution) and then calculating expected completion times based on the results. My aim in this post is to present an example-based introduction to Monte Carlo simulation of project task durations.
Although my aim is to keep things reasonably simple (not too much beyond high-school maths and a basic understanding of probability), I’ll be covering a fair bit of ground. Given this, I’d best to start with a brief description of my approach so that my readers know what coming.
Monte Carlo simulation is an umbrella term that covers a range of approaches that use random sampling to simulate events that are described by known probability distributions. The first task then, is to specify the probability distribution. However, as mentioned earlier, this is generally unknown for task durations. For simplicity, I’ll assume that task duration uncertainty can be described accurately using a triangular probability distribution – a distribution that is particularly easy to handle from the mathematical point of view. The advantage of using the triangular distribution is that simulation results can be validated easily.
Using the triangular distribution isn’t a limitation because the method I describe can be applied to arbitrarily shaped distributions. More important, the technique can be used to simulate what happens when multiple tasks are strung together as in a project schedule (I’ll cover this in a future post). Finally, I’ll demonstrate a Monte Carlo simulation method as applied to a single task described by a triangular distribution. Although a simulation is overkill in this case (because questions regarding durations can be answered exactly without using a simulation), the example serves to illustrate the steps involved in simulating more complex cases – such as those comprising of more than one task and/or involving more complicated distributions.
So, without further ado, let me begin the journey by describing the triangular distribution.
The triangular distribution
Let’s assume that there’s a project task that needs doing, and the person who is going to do it reckons it will take between 2 and 8 hours to complete it, with a most likely completion time of 4 hours. How the estimator comes up with these numbers isn’t important at this stage – maybe there’s some guesswork, maybe some padding or maybe it is really based on experience (as it should be). What’s important is that we have three numbers corresponding to a minimum, most likely and maximum time. To keep the discussion general, we’ll call these 


Now, what about the probabilities associated with each of these times?
Since 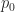
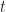

Figure 1: Triangular Distribution
For the simulation, we need to know the equation describing the above distribution. Although Wikipedia will tell us the answer in a mouse-click, it is instructive to figure it out for ourselves. First, note that the area under the triangle must be equal to 1 because the task must finish at some time between
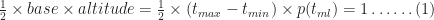
where 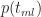
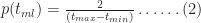
To derive the probability for any time
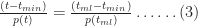
This is a consequence of the fact that the ratios on either side of equation (3) are equal to the slope of the line joining the points 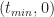
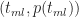

Figure 2
Substituting (2) in (3) and simplifying a bit, we obtain:
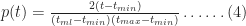
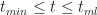
In a similar fashion one can show that the probability for times lying between
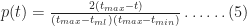

Equations 4 and 5 together describe the probability distribution function (or PDF) for all times between
Another quantity of interest is the cumulative distribution function (or CDF) which is the probability, 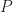
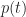
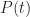

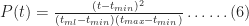
Noting that for 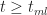
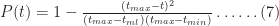
As expected,
To end this section let's plug in the numbers quoted by our estimator at the start of this section: 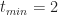
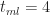
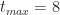


Figure 4 – Triangular CDF (tmin=2, tml=4, tmax=8)
Monte Carlo Simulation of a Single Task
OK, so now we get to the business end of this essay – the simulation. I’ll first outline the simulation procedure and then discuss results for the case of the task described in the previous section (triangular distribution with
So, here’s my simulation procedure:
- Generate a random number between 0 and 1. Treat this number as the cumulative probability,
- Find the time,
- Repeat steps (1) and (2) N times, where N is a “sufficiently large” number – say 10,000.
I did the calculations for 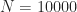
As an example of a simulation run proceeds, here’s the data from my first simulation run: the random number generator returned 0.490474700804856 (call it 0.4905). This is the value of 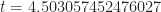

Figure 5
After completing 10,000 simulation runs, I sorted these into bins corresponding to time intervals of .25 hrs, starting from

Figure 6: Distribution of simulation runs
As one might expect, this looks like the triangular distribution shown in Figure 4. There is a difference though: Figure 4 plots probability as a continuous function of time whereas Figure 6 plots the number of simulation runs as a step function of time. To convince ourselves that the two are really the same, lets look at the cumulative probability at 
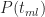
Wrap up
A limitation of the triangular distribution is that it imposes an upper cut-off at
Another point worth mentioning is that simulations can be done at a level higher than that of an indivdual task. In their brilliant book – Waltzing With Bears: Managing Risk on Software Projects – De Marco and Lister demonstrate the use of Monte Carlo methods to simulate various aspects of project – velocity, time, cost etc. – at the project level (as opposed to the task level). I believe it is better to perform simulations at the lowest possible level (although it is a lot more work) – the main reason being that it is easier, and less error-prone, to estimate individual tasks than entire projects. Nevertheless, high level simulations can be very useful if one has reliable data to base these on.
I would be remiss if I didn’t mention some of the various Monte Carlo packages available in the market. I’ve never used any of these, but by all accounts they’re pretty good: see this commercial package or this one, for example. Both products use random number generators and sampling techniques that are far more sophisticated than the simple ones I’ve used in my example.
Finally, I have to admit that the example described in this post is a very complicated way of demonstrating the obvious – I started out with the triangular distribution and then got back the triangular distribution via simulation. My point, however, was to illustrate the method and show that it yields expected results in a situation where the answer is known. In a future post I’ll apply the method to more complex situations- for example, multiple tasks in series and parallel, with some dependency rules thrown in for good measure. Although, I’ll use the triangular distribution for individual tasks, the results will be far from obvious: simulation methods really start to shine as complexity increases. But all that will have to wait for later. For now, I hope my example has helped illustrate how Monte Carlo methods can be used to simulate project tasks.
Note added on 21 Sept 2009:
Follow-up to this article published here.
Note added on 14 Dec 2009:
See this post for a Monte Carlo simulation of correlated project tasks.
Anchored and over-optimistic: why quick and dirty estimates are almost always incorrect
Some time ago, a sales manager barged into my office. “I’m sorry for the short notice,” she said, “but you’ll need to make some modifications to the consolidated sales report by tomorrow evening.”
I could see she was stressed and I wanted to help, but there was an obvious question that needed to be asked. “What do you need done? I’ll have to get some details before I can tell you if it can be done within the time,” I replied.
She pulled up a chair and proceeded to explain what was needed. Within a minute or two I knew there was no way I could get it finished by the next day. I told her so.
“Oh no…this is really important. How long will it take?”
I thought about it for a minute or so. “OK how about I try to get it to you by day after?”
“Tomorrow would be better, but I can wait till day after.” She didn’t look very happy about it though. “Thanks,” she said and rushed away, not giving me a chance to reconsider my off-the-cuff estimate.
—
After she left, I had a closer look at what needed to be done. Soon I realised it would take me at least twice as long if I wanted to do it right. As it was, I’d have to work late to get it done in the agreed time, and may even have to cut a corner or two ( or three) in the process.
So why was I so wide off the mark?
I had been railroaded into giving the manager an unrealistic estimate without even realising it. When the manager quoted her timeline, my subconscious latched on to it as an initial value for my estimate. Although I revised the initial estimate upwards, I was “pressured” – albeit unknowingly – into quoting an estimate that was biased towards the timeline she’d mentioned. I was a victim of what psychologists call anchoring bias – a human tendency to base judgements on a single piece of information or data, ignoring all other relevant factors. In arriving at my estimate, I had focused on one piece of data (her timeline) to the exclusion of all other potentially significant information (the complexity of the task, other things on my plate etc.).
Anchoring bias was first described by Amos Tversky and Daniel Kahnemann in their pioneering paper entitled, Judgement under Uncertainty: Heuristics and Biases. Tversky and Kahnemann found that people often make quick judgements based on initial (or anchor) values that are suggested to them. As the incident above illustrates, the anchor value (the manager’s timeline) may have nothing to do with the point in question (how long it would actually take me to do the work). To be sure, folks generally adjust the anchor values based on other information. These adjustments, however, are generally inadequate. The final estimates arrived at are incorrect because they remain biased towards the initial value. As Tversky and Kahnemann state in their paper:
In many situations, people make estimates by starting from an initial value that is adjusted to yield the final answer. The initial value, or starting point, may be suggested by the formulation of the problem, or it may be the result of a partial computation. In either case, adjustments are typically insufficient. That is, different starting points yield different estimates, which are biased toward the initial values. We call this phenomenon anchoring.
Although the above quote may sound somewhat academic, be assured that anchoring is very real. It affects even day-to-day decisions that people make. For example, in this paper Neil Stewart presents evidence that credit card holders repay their debt more slowly when their statements suggest a minimum payment. In other words the minimum payment works as an anchor, causing the card holder to pay a smaller amount than they would have been prepared to (in the absence of an anchor).
Anchoring, however, is only part of the story. Things get much worse for complex tasks because another bias comes into play. Tversky and Kahnemann found that subjects tended to be over optimistic when asked to make predictions regarding complex matters. Again, quoting from their paper:
Biases in the evaluation of compound events are particularly significant in the context of planning. The successful completion of an undertaking, such as the development of a new product, typically has a conjunctive character: for the undertaking to succeed, each of a series of events must occur. Even when each of these events is very likely, the overall probability of success can be quite low if the number of events is large. The general tendency to overestimate the probability of conjunctive events leads to unwarranted optimism in the evaluation of the likelihood that a plan will succeed or that a project will be completed on time.
Such over-optimism in the face of complex tasks is sometimes referred to as the planning fallacy.1
Of course, as discussed by Kahnemann and Fredrick in this paper, biases such as anchoring and the planning fallacy can be avoided by a careful, reflective approach to estimation – as opposed to a “quick and dirty” or intuitive one. Basically, a reflective approach seeks to eliminate bias by reducing the effect of individual judgements. This is why project management texts advise us (among other things) to:
- Base estimates on historical data for similar tasks. This is the basis of reference class forecasting which I have written about in an earlier post.
- Draft independent experts to do the estimation.
- Use multipoint estimates (best and worst case scenarios)
In big-bang approaches to project management, one has to make a conscious effort to eliminate bias because there are fewer chances to get it right. On the other hand, iterative / incremental methodologies have bias elimination built-in because one starts with initial estimates, which include inaccuracies due to bias, and subsequently refine these as one progresses. The estimates get better as one goes along because every refinement is based on an improved knowledge of the task.
Anchoring and the planning fallacy are examples cognitive biases – patterns of deviations of judgement that humans display in a variety of situations. Since the pioneering work of Tversky and Kahnemann, these biases have been widely studied by psychologists. It is important to note that these biases come into play whenever quick and dirty judgements are involved. They occur even when subjects are motivated to make accurate judgements. As Tversky and Kahnemann state towards the end of their paper:
These biases are not attributable to motivational effects such as wishful thinking or the distortion of judgments by payoffs and penalties. Indeed, several of the severe errors of judgment reported earlier (in the paper) occurred despite the fact that subjects were encouraged to be accurate and were rewarded for the correct answers.
The only way to avoid cognitive biases in estimating is to proceed with care and consideration. Yes, that’s a time consuming, effort-laden process, but that’s the price one pays for doing it right. To paraphrase Euclid, there is no royal road to estimation.
1 The planning fallacy is related to optimism bias which I have discussed in my post on reference class forecasting.
A pert myth
PERT (Program Evaluation and Review Technique) is a stock standard method to manage project schedule risk. It is taught (or at least mentioned) in just about every project management course. PERT was first used (and is considered to have originated) in the Polaris project, and is often credited as being one of the main reasons for the the success of that endeavour. The truth is considerably more nuanced: it turns out that PERT was used on the Polaris project more as PR than PM. It was often applied “after the fact” – when generating reports for Congress, who held the project purse-strings. This post is a brief look into the PERT myth, based on sources available online.
An excellent place to start is Glen Alleman’s post from 2005 entitled, Origins and Myth of PERT1. Glen draws attention to a RAND Corporation publication entitled, Quantitative Risk Analysis for Project Management – A Critical Review, written by Lionel Galway. The paper is essentially a survey of quantitative risk management and analysis techniques. The author has this to say about PERT:
…PERT was a great success from a public relations point of view, although only a relatively small portion of the Polaris program was ever managed using the technique. And this success led to adaptations of PERT such as PERT/cost that attempted to address cost issues as well. While PERT was widely acclaimed by the business and defense communities in the 1960s, later studies raised doubts about whether PERT contributed much to the management success of the Polaris project. Many contended that its primary contribution was to deflect management interference by the Navy and DoD (Department of Defense) by providing a “cover” of disciplined, quantitative, management carried out by modern methodologies…
Then, in the conclusion of the paper, he states:
…While the Polaris program touted PERT as a breakthrough in project management, as noted above not even a majority of the tasks in the project were controlled with PERT. Klementowski’s thesis in the late 1970s, although limited for generalization by the sampling technique, showed less than a majority of organizations using CPM/PERT techniques. And the interviews conducted for this report revealed a similar ambivalence: respondents affirmed the usefulness of the techniques in general, but did not provide much in the way of particular examples…
In a footnote on page 10 of the paper, the author draws attention to Sapolsky’s book The Polaris System Development: Bureaucratic and Programmatic Success in Government. Among other things, the book describes how the use of PERT on the project has been grossly overstated. Unfortunately the book is out of print, but there is an excellent review of it on Cadmus. The review has this to say about the use of PERT on the Polaris project:
…SPO (Special Projects Office) Director Vice Admiral William F. Raborn pushed PERT mercilessly. The colorful PERT charts impressed everyone, and coupled with the nature of the project, they exuded management “sex appeal.” This kept other DoD poachers at bay and politicians off SPO’s back. Other government services became so enamored with PERT, they quickly made it a requirement in subsequent contracts.A more objective assessment of PERT is that the network analysis2 is the major benefit. PERT can reduce cost and time overruns, and make its practitioners look like better managers…
The Royal Navy knew of the over-inflated success of PERT when it embarked on its own Polaris program in the 1960’s. The Royal Navy deliberately adopted PERT, essentially to keep Whitehall, Parliament and other critics away from their project. It worked just as well for the RN as it did for the USN
…
I found the accounts of PERT presented in these sources fascinating, because they highlight how project management history can be so much more ambiguous (and messier) than textbooks, teachers and trainers would have us believe. Techniques are often taught without any regard to their origins and limitations. Thus disassociated from their origins, they take on a life of their own leading to myths where from it is difficult to separate fact from fiction.
1 Glen Alleman also discusses some limitations of PERT in this and another post on his blog.
2 Network analysis refers to task sequencing (precedence and dependencies) rather than task durations.


