Archive for the ‘IT Management’ Category
The proof of concept – a business fable
The Head of Data Management was a troubled man. The phrase “Big Data” had cropped up more than a few times in a lunch conversation with Jack, a senior manager from Marketing.
Jack had pointedly asked what the data management team was doing about “Big Data”…or whether they were still stuck in a data time warp. This comment had put the Head of Data Management on the defensive. He’d mumbled something about a proof of concept with vendors specializing in Big Data solutions being on the drawing board.
He spent the afternoon dialing various vendors in his contact list, setting up appointments to talk about what they could offer. His words were music to the vendors’ ears; he had no trouble getting them to bite.
The meetings went well. He was soon able to get a couple of vendors to agree to doing proofs of concept, which amounted to setting up trial versions of their software on the organisation’s servers, thus giving IT staff an opportunity to test-drive and compare the vendors’ offerings.
The software was duly installed and the concept duly proven.
…but the Head of Data Management was still a troubled man.
He had sought an appointment with Jack to inform him about the successful proof of concept. Jack had listened to his spiel, but instead of being impressed had asked a simple question that had the Head of Data Management stumped.
“What has your proof of concept proved?” Jack asked.
“What do…do you mean?” stammered the Head of Data Management.
“I don’t think I can put it any clearer than I already have. What have you proved by doing this so-called proof of concept?”
“Umm… we have proved that the technology works,” came the uncertain reply.
“Surely we know that the technology works,” said Jack, a tad exasperated.
“Ah, but we don’t know that it works for us,” shot back the Head of Data Management.
“Look, I’m just a marketing guy, I know very little about IT,” said Jack, “but I do know a thing or two about product development and marketing. I can say with some confidence that the technology– whatever it is – does what it is supposed to do. You don’t need to run a proof of concept to prove that it works. I’m sure the vendors would have done that before they put their product on the market. So, my question remains: what has your proof of concept proved?”
“Well we’ve proved that it does work for us…:
“Proved it works for what??” asked Jack, exasperation mounting. “Let me put it as clearly as I can – what business problem have you solved that you could not address earlier.”
“Well we’ve taken some of the data from our largest databases – the sales database, from your area of work, and loaded it into the Big Data infrastructure.”
“…and then what?”
“Well that’s about it…for now.”
“So, all you have is another database. You haven’t actually done anything that cannot be done on our existing databases. You haven’t tackled a business problem using your new toy,” said Jack.
“Yes, but this is just the start. We’ll now start doing analytics and all that other stuff we were talking about.”
“I’m sorry to say, this is a classic example of putting the cart before the horse,” said Jack, shaking his head in disbelief.
“How so?” challenged the Head of Data Management.
“Should be obvious but may be it isn’t, so let me spell it out. You’ve jumped to a solution – the technology you’ve installed – without taking the time to define the business problems that the technology should address.”
“…but…but you talked about Big Data when we had lunch the other day.”
“Indeed I did. And what I expected was the start of a dialogue between your people and mine about the kinds of problem we would like to address. We know our problems well, you guys know the technology; but the problems should always drive the solution. What you’ve done now is akin to a solution in search of a problem, a cart before a horse”
“I see,” said the Head of Data Management slowly.
And Jack could only hope that he really did see.
Disclaimer:
This is a work of fiction. It could never happen in real life 😉
Setting up an internal data analytics practice – some thoughts from a wayfarer
Introduction
This year has been hugely exciting so far: I’ve been exploring and playing with various techniques that fall under the general categories of data mining and text analytics. What’s been particularly satisfying is that I’ve been fortunate to find meaningful applications for these techniques within my organization.
Although I have a fair way to travel yet, I’ve learnt that common wisdom about data analytics – especially the stuff that comes from software vendors and high-end consultancies – can be misleading, even plain wrong. Hence this post in which I dispatch some myths and share a few pointers on establishing data analytics capabilities within an organization.
Busting a few myths
Let’s get right to it by taking a critical look at a few myths about setting up an internal data analytics practice.
- Requires high-end technology and a big budget: this myth is easy to bust because I can speak from recent experience. No, you do not need cutting-edge technology or an oversized budget. You can get started for with an outlay of 0$ – yes, that’s right, for free! All you need to is the open-source statistical package R (check out this section of my article on text mining for more on installing and using R) and the willingness to roll-up your sleeves and learn (more about this later). No worries if you prefer to stick with familiar tools – you can even begin with Excel.
- Needs specialist skills: another myth floating around is that you need Phd level knowledge in statistics or applied mathematics to do practical work in analytics. Sorry, but that’s plain wrong. You do need a PhD to do research in the analytics and develop your own algorithms, but not if you want to apply algorithms written by others.Yes, you will need to develop an understanding of the algorithms you plan to use, a feel for how they work and the ability to tell whether the results make sense. There are many good resources that can help you develop these skills – see, for example, the outstanding books by James, Witten, Hastie and Tibshirani and Kuhn and Johnson.
- Must have sponsorship from the top: this one is possibly a little more controversial than the previous two. It could be argued that it is impossible to gain buy in for a new capability without sponsorship from top management. However, in my experience, it is OK to start small by finding potential internal “customers” for analytics services through informal conversations with folks in different functions.I started by having informal conversations with managers in two different areas: IT infrastructure and sales / marketing. I picked these two areas because I knew that they had several gigabytes of under-exploited data – a good bit of it unstructured – and a lot of open questions that could potentially be answered (at least partially) via methods of data and text analytics. It turned out I was right. I’m currently doing a number of proofs of concept and small projects in both these areas. So you don’t need sponsorship from the top as long as you can get buy in from people who have problems they believe you can solve. If you deliver, they may even advocate your cause to their managers.
A caveat is in order at this point: my organization is not the same as yours, so you may well need to follow a different path from mine. Nevertheless, I do believe that it is always possible to find a way to start without needing permission or incurring official wrath. In that spirit, I now offer some suggestions to help kick-start your efforts
Getting started
As the truism goes, the hardest part of any new effort is getting started. The first thing to keep in mind is to start small. This is true even if you have official sponsorship and a king-sized budget. It is very tempting to spend a lot of time garnering management support for investing in high-end technology. Don’t do it! Do the following instead:
- Develop an understanding of the problems faced by people you plan to approach: The best way to do this is to talk to analysts or frontline managers. In my case, I was fortunate to have access to some very savvy analysts in IT service management and marketing who gave me a slew of interesting ideas to pursue. A word of advice: it is best not to talk to senior managers until you have a few concrete results that you can quantify in terms of dollar values.
- Invest time and effort in understanding analytics algorithms and gaining practical experience with them: As mentioned earlier, I started with R – and I believe it is the best choice. Not just because it is free but also because there are a host of packages available to tackle just about any analytics problem you might encounter. There are some excellent free resources available to get you started with R (check out this listing on the r-statistics blog, for example).It is important that you start cutting code as you learn. This will help you build a repertoire of techniques and approaches as you progress. If you get stuck when coding, chances are you will find a solution on the wonderful stackoverflow site.
- Evangelise, evangelise, evangelise: You are, in effect, trying to sell an idea to people within your organization. You therefore have to identify people who might be able to help you and then convince them that your idea has merit. The best way to do the latter is to have concrete examples of problems that you have tackled. This is a chicken-and-egg situation in that you can’t have any examples until you gain support. I got support by approaching people I know well. I found that most – no, all – of them were happy to provide me with interesting ideas and access to their data.
- Begin with small (but real) problems: It is important to start with the “low-hanging fruit” – the problems that would take the least effort to solve. However, it is equally important to address real problems, i.e. those that matter to someone.
- Leverage your organisation’s existing data infrastructure: From what I’ve written thus far, I may have given you the impression that the tools of data analytics stand separate from your existing data infrastructure. Nothing could be further from the truth. In reality, I often do the initial work (basic preprocessing and exploratory analysis) using my organisation’s relational database infrastructure. Relational databases have sophisticated analytical extensions to SQL as well as efficient bulk data cleansing and transport facilities. Using these make good sense, particularly if your R installation is on a desktop or laptop computer as it is in my case. Moreover, many enterprise database vendors now offer add-on options that integrate R with their products. This gives you the best of both worlds – relational and analytical capabilities on an enterprise-class platform.
- Build relationships with the data management team: Remember the work you are doing falls under the ambit of the group that is officially responsible for managing data in your organization. It is therefore important that you keep them informed of what you’re doing. Sooner or later your paths will cross, and you want to be sure that there are no nasty surprises (for either side!) at that point. Moreover, if you build connections with them early, you may even find that the data management team supports your efforts.
Having waxed verbose, I should mention that my effort is work in progress and I do not know where it will lead. Nevertheless, I offer these suggestions as a wayfarer who is considerably further down the road from where he started.
Parting thoughts
You may have noticed that I’ve refrained from using the overused and over-hyped term “Big Data” in this piece. This is deliberate. Indeed, the techniques I have been using have nothing to do with the size of the datasets. To be honest, I’ve applied them to datasets ranging from a few thousand to a few hundred thousand records, both of which qualify as Very Small Data in today’s world.
Your vendor will be only too happy to sell you Big Data infrastructure that will set you back a good many dollars. However, the chances are good that you do not need it right now. You’ll be much better off going back to them after you hit the limits of your current data processing infrastructure. Moreover, you’ll also be better informed about your needs then.
You may also be wondering why I haven’t said much about the composition of the analytics team (barring the point about not needing PhD statisticians) and how it should be organized. The reason I haven’t done so is that I believe the right composition and organizational structure will emerge from the initial projects done and feedback received from internal customers. The resulting structure will be better suited to the organization than one that is imposed upfront. Long time readers of this blog might recognize this as a tenet of emergent design.
Finally, I should reiterate that my efforts are still very much in progress and I know not where they will lead. However, even if they go nowhere, I would have learnt something about my organization and picked up a useful, practical skill. And that is good enough for me.
TOGAF or not TOGAF… but is that the question?
“The ‘Holy Grail’ of effective collaboration is creating shared understanding, which is a precursor to shared commitment.” – Jeff Conklin.
“Without context, words and actions have no meaning at all.” – Gregory Bateson.
I spent much of last week attending a class on the TOGAF Enterprise Architecture (EA) framework. Prior experience with IT frameworks such as PMBOK and ITIL had taught me that much depends on the instructor – a good one can make the material come alive whereas a not-so-good one can make it an experience akin to watching grass grow. I needn’t have worried: the instructor was superb, and my classmates, all of whom are experienced IT professionals / architects, livened up the proceedings through comments and discussions both in class and outside it. All in all, it was a thoroughly enjoyable and educative experience, something I cannot say for many of the professional courses I have attended.
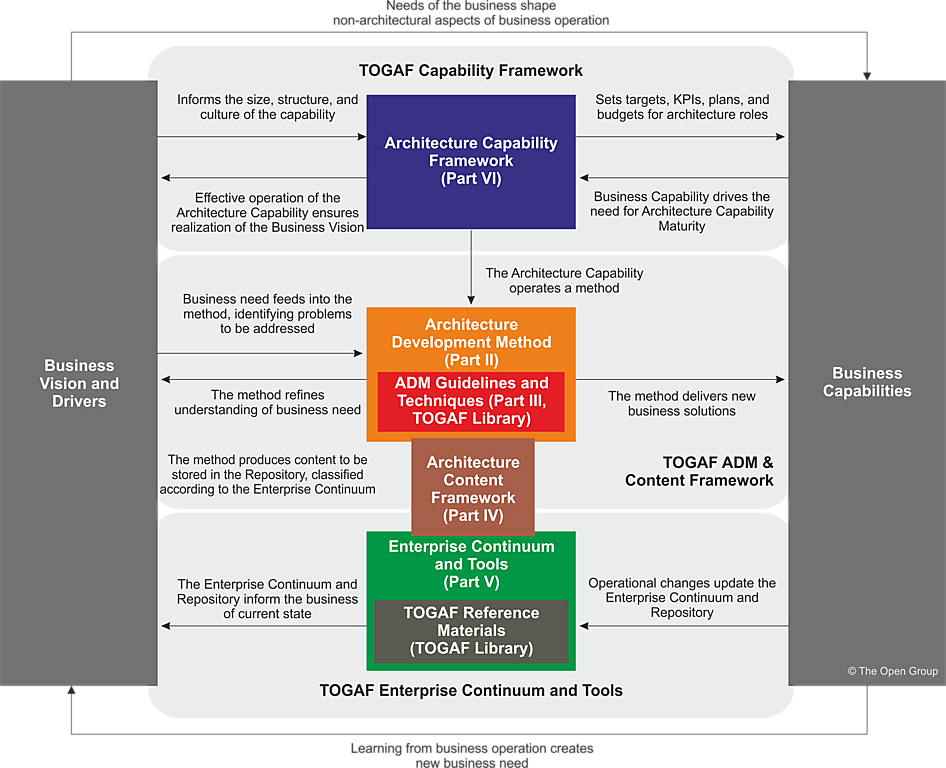
One of the things about that struck me about TOGAF is the way in which the components of the framework hang together to make a coherent whole (see the introductory chapter of the framework for an overview). To be sure, there is a lot of detail within those components, but there is a certain abstract elegance – dare I say, beauty – to the framework.
That said TOGAF is (almost) entirely silent on the following question which I addressed in a post late last year:
Why is Enterprise Architecture so hard to get right?
Many answers have been offered. Here are some, extracted from articles published by IT vendors and consultancies:
- Lack of sponsorship
- Not engaging the business
- Inadequate communication
- Insensitivity to culture / policing mentality
- Clinging to a particular tool or framework
- Building an ivory tower
- Wrong choice of architect
(Note: the above points are taken from this article and this one)
It is interesting that the first four issues listed are related to the fact that different stakeholders in an organization have vastly different perspectives on what an enterprise architecture initiative should achieve. This lack of shared understanding is what makes enterprise architecture a socially complex problem rather than a technically difficult one. As Jeff Conklin points out in this article, problems that are technically complex will usually have a solution that will be acceptable to all stakeholders, whereas socially complex problems will not. Sending a spacecraft to Mars is an example of the former whereas an organization-wide ERP (or EA!) project or (on a global scale) climate change are instances of the latter.
Interestingly, even the fifth and sixth points in the list above – framework dogma and retreating to an ivory tower – are usually consequences of the inability to manage social complexity. Indeed, that is precisely the point made in the final item in the list: enterprise architects are usually selected for their technical skills rather than their ability to deal with ambiguities that are characteristic of social complexity.
TOGAF offers enterprise architects a wealth of tools to manage technical complexity. These need to be complemented by a suite of techniques to reconcile worldviews of different stakeholder groups. Some examples of such techniques are Soft Systems Methodology, Polarity Management, and Dialogue Mapping. I won’t go into details of these here, but if you’re interested, please have a look at my posts entitled, The Approach – a dialogue mapping story and The dilemmas of enterprise IT for brief introductions to the latter two techniques via IT-based examples.
<Advertisement > Better yet, you could check out Chapter 9 of my book for a crash course on Soft Systems Methodology and Polarity Management and Dialogue Mapping, and the chapters thereafter for a deep dive into Dialogue Mapping </Advertisement>.
Apart from social complexity, there is the problem of context – the circumstances that shape the unique culture and features of an organization. As I mentioned in my introductory remarks, the framework is abstract – it applies to an ideal organization in which things can be done by the book. But such an organization does not exist! Aside from unique people-related and political issues, all organisations have their own quirks and unique features that distinguish them from other organisations, even within the same domain. Despite superficial resemblances, no two pharmaceutical companies are alike. Indeed, the differences are the whole point because they are what make a particular organization what it is. To paraphrase the words of the anthropologist, Gregory Bateson, the differences are what make a difference.
Some may argue that the framework acknowledges this and encourages, even exhorts, people to tailor the framework to their needs. Sure, the word “tailor” and its variants appear almost 700 times in the version 9.1 of the standard but, once again, there is no advice offered on how this tailoring should be done. And one can well understand why: it is impossible to offer any sensible advice if one doesn’t know the specifics of the organization, which includes its context.
On a related note, the TOGAF framework acknowledges that there is a hierarchy of architectures ranging from the general (foundation) to the specific (organization). However despite the acknowledgement of diversity, in practice TOGAF tends to focus on similarities between organisations. Most of the prescribed building blocks and processes are based on assumed commonalities between the structures and processes in different organisations. My point is that, although similarities are important, architects need to focus on differences. These could be differences between the organization they are working in and the TOGAF ideal, or even between their current organization and others that they have worked with in the past (and this is where experience comes in really handy). Cataloguing and understanding these unique features – the differences that make a difference – draws attention to precisely those issues that can cause heartburn and sleepless nights later.
I have often heard arguments along the lines of “80% of what we do follows a standard process, so it should be easy for us to standardize on a framework.” These are famous last words, because some of the 20% that is different is what makes your organization unique, and is therefore worthy of attention. You might as well accept this upfront so that you get a realistic picture of the challenges early in the game.
To sum up, frameworks like TOGAF are abstractions based on an ideal organization; they gloss over social complexity and the unique context of individual organisations. So, questions such as the one posed in the title of this post are akin to the pseudo-choice between Coke and Pepsi, for the real issue is something else altogether. As Tom Graves tells us in his wonderful blog and book, the enterprise is a story rather than a structure, and its architecture an ongoing sociotechnical drama.



{kind=link}