Archive for the ‘IT Management’ Category
Routines and reality – on the gap between the design and use of enterprise systems
Introduction
Enterprise IT systems that are built or customised according to specifications sometimes fail because of lack of adoption by end-users. Typically this is treated as a problem of managing change, and is dealt with in the standard way: by involving key stakeholders in system design, keeping them informed of progress, generating and maintaining enthusiasm for the new system and, most important, spending enough time and effort in comprehensive training programmes.
Yet these efforts are sometimes in vain and the question, quite naturally, is: “Why?” In this post I offer an answer, drawing on a paper by Brian Pentland and Martha Feldman entitled, Designing Routines: On the Folly of Designing Artifacts While Hoping for Patterns of Action.
Setting the context
From a functional point of view, enterprise software embodies organisational routines – i.e. sequences of actions that have well-defined objectives, and are typically performed by business users in specific contexts. Pentland and Feldman argue that although enterprise IT systems tend to treat organisational routines as well defined processes (i.e. as objects), it is far from obvious that they are so. Indeed, the failure of business process “design” or “redesign” initiatives can often be traced back to a fundamental misunderstanding of what organisational routines are. This is a point that many system architects, designers and even managers / executives would do well to understand.
As Pentland and Feldman state:
… the frequent disconnect between [system or design] goals and results arises, at least in part, because people design artifacts when they want patterns of action…we believe that designing things while hoping for patterns of action is a mistake. The problem begins with a failure to understand the nature of organizational routines, which are the foundation of any work process that involves coordination among multiple actors… even today, organizational routines are widely misunderstood as rigid, mundane, mindless, and explicitly stored somewhere. With these mistaken assumptions as a starting point, designing new work routines would seem to be a simple matter of creating new checklists, rules, procedures, and software. Once in place, these material artifacts will determine patterns of action: software will be used, checklists will get checked, and rules will be followed.
The fundamental misunderstanding is that design artifacts, checklists, and rules and procedures encoded in software are mistaken for the routine instead of being seen for what they are: idealised representations of the routine. Many software projects fail because designers do not understand this. The authors describe a case study that highlights this point and then draw some general inferences from it. I describe the case study in the next section and then look into what can be learnt from it.
The situation
The case study deals with a packaged software implementation at a university. The university had two outreach programs that were quite similar, but were administered independently by two different departments using separate IT systems. Changes in the university IT infrastructure meant that one of the departments would lose the mainframe that hosted their system.
An evaluation was performed, and the general consensus was that it would be best for the department losing the mainframe to start using the system that the other department was using. However, this was not feasible because the system used by the other department was licensed only for a single user. It was therefore decided to upgrade to a groupware version of the product. Since the proposed system was intended to integrate the outreach-related work of the two departments, this also presented an opportunity to integrate some of the work processes of the two departments.
A project team was set-up, drawing on expertise from both departments. Requirements were gathered and a design was prepared based on the requirements. The system was customised and tested as per the design, and data from the two departments was imported from the old systems into the new one. Further, the project team knew the importance of support and training: additional support was organised as were training sessions for all users.
But just as everything seemed set to go, things started to unravel. In the author’s words:
As the launch date grew nearer, obstacles emerged. The implementation met resistance and stalled. After dragging their feet for weeks, [the department losing the mainframe] eventually moved their data from the mainframe to a stand-alone PC and avoided [the new system] entirely. The [other department] eventually moved over [to the new system], but used only a subset of the features. Neither group utilized any of the functionality for accounting or reporting, relying instead on their familiar routines (using standalone spreadsheets) for these parts of the work. The carefully designed vision of unified accounting and reporting did not materialize.
People in the department that was losing the mainframe worked around the new system by migrating their data to a standalone PC and using that to run their own system. People in the other department did migrate to the new system, but used only a small subset of its features.
All things considered, the project was a failure.
So what went wrong?
The authors emphasise that the software was more than capable of meeting the needs of both departments, so technical or even functional failure can be ruled out as a reason for non-adoption. On speaking with users, they found that the main objections to the system had to with the work patterns that were imposed by it. Specifically, people objected to having to give up control over their work practices and their identities (as members of specific) departments. There was a yawning gap between the technical design of the system and the work processes as they were understood and carried out by people in the two departments.
The important thing to note here is that people found ways to work around the system despite the fact that the system actually worked as per the requirements. The system failed despite being a technical success. This is a point that those who subscribe to the mainstream school of enterprise system design and architecture would do well to take note of.
Dead and live routines
The authors go further: to understand resistance to change, they invoke the notion of dead and live routines. Dead routines are those that have been represented in technical artifacts such as documentation, flowcharts, software etc. whereas live routines are those that are actually executed by people. The point is, live routines are literally living objects – they evolve in idiosyncratic ways because people inevitably tweak them, sometimes even without being conscious that they are making changes. As a consequence live routines often generate new patterns of action.
The crux of the problem is that software is capable of representing dead routines, not live ones.
Complementary aspects of routines
Routines are composed of people’s understandings of the routines (the authors call this the ostensive aspect) and the way in which they are actually performed or carried out (the authors call this the performative aspect). The two aspects, the routine as understood and the routine as performed, complement each other: new actions will modify one’s understanding of a routine, and the new understanding in turn modifies future actions.
Now, the interesting thing is that no artifact can represent all aspects of a routine – something is always left out. Even though certain artifacts such as written procedures may be intended to change both the ostensive and performative aspects of a routine (as they usually are), there is no guarantee that they will actually influence behaviour. Managers who encounter resistance to change will have had first-hand experience of this: it is near impossible to force change upon a group that does not want it.
This leads us to another set of complementary aspects of routines. On the one hand, technology puts in place structures that enable certain actions while constraining others – this is the standard technological or material view of processes as represented in systems. In contrast, according to the social or agency view, people are free to use technology in whatever way they like and sometimes even not use it at all. In the case study, the former view was the one that designers took whereas users focused on the latter one.
The main point to take away from the foregoing discussion is that designers/ engineers and users often have very different perspectives on processes. Software that is based on a designer/engineer perspective alone will invariably end up causing problems for end users.
Routines and reality
Traditional systems design proceeds according to the following steps:
- Gather requirements
- Analyse and encode them in rules
- Implement rules in a software system
- Provide people with incentives and training to follow the rules
- Rollout the system
Those responsible for the implementation of the system described in the case study followed the steps faithfully, yet the system failed because one department didn’t use it at all and the other used it selectively. The foregoing discussion tells us that the problem arises from confusing artifacts with actions, or as I like to put it, routines with reality.
As the authors write:
This failure to understand the difference between artifacts and actions is not new…the failure to distinguish the social (or human) from the technical is a “category mistake.” Mistakenly treating people like machines (rule-following automata) results in a wide range of undesirable, but not entirely surprising, outcomes. This category difference has been amply demonstrated for individuals, but it applies equally (if not more so) to organizational routines. This is because members’ embodied and cognitive understandings are often diverse, multiple, and conflicting.
The failure to understand the difference between routines and reality is not new, but it appears that the message is yet to get through: organisations continue to implement (new routines via) enterprise systems without putting in the effort to understand ground-level reality.
Some tips for designers
The problem of reconciling user and designer perspectives is not an easy one. Nevertheless, the authors describe an approach that may prove useful to some. The first concept is that of a narrative network – a collection of functional events that are related by the sequence in which they occur. A functional event is one in which two actants (or objects that participate in a routine) are linked by an action. The actants here could be human or non-human and the action represents a step in the process. Examples of functional events would be:
- The sales rep calls on the customer.
- The customer orders a product.
- The product is shipped to the customer.
The important thing to note is that the functional event does not specify how the process is carried out – that can be done in a myriad different ways. For example, the sales rep may meet the customer face-to-face or she may just make a phone call. The event only specifies the basic intent of the action, not the detail of how it is to be carried out. This leaves open the possibility for improvisation if the situation calls for it. More importantly it places the responsibility for making that decision on the person responsible for the carrying out the action (in the case of a human actant).
Then it is useful to classify a functional event based on the type of actants participating in the event – human or (non-human) artifact. There are four possibilities as shown in Figure 1.
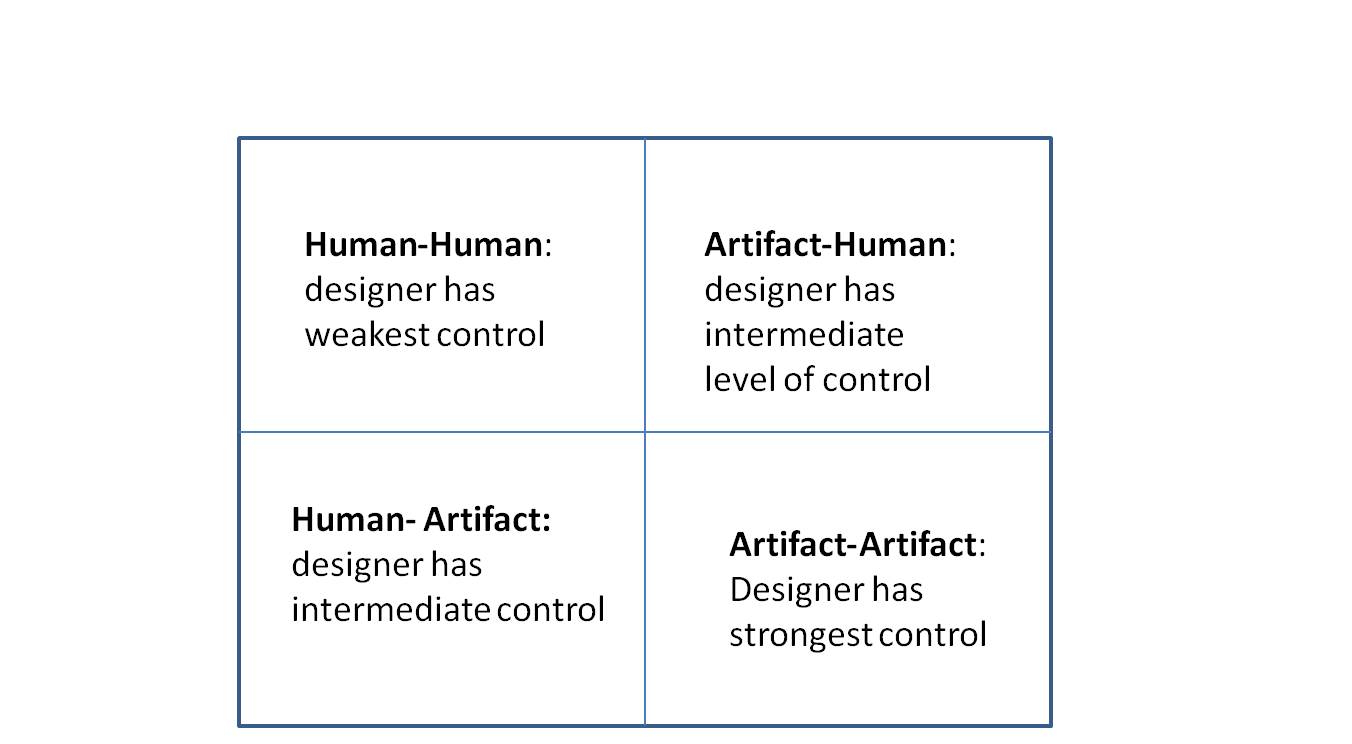
Figure 1: Human-artifact grid
The interesting thing to note is that from the perspective of system design, an artifact-artifact event is one over which the designer has the strongest control (actions involving only artifacts can be automated) whereas a designer’s influence is the weakest in human-human events (humans rarely, if ever, do exactly as they are told!). Decomposing a routine in this way can thus serve to focus designer efforts in areas where they are likely to pay off and, more importantly, help them understand where they are likely to get some push back.
Finally, there are some general points to consider when designing a system. These include:
- Reinforce the patterns of the routine: Much as practise makes an orchestra perform better, organisations have to invest in practicing the routines. Practice connects the abstract routine to the performed one.
- Consider every stakeholder group’s point of view: This is a point I have elaborated at length in my posts on dialogue mapping so I’ll say no more about it here.
- Understand the relationship between abstract patterns and actual performances: This involves understanding whether there are different ways to achieve the same goal. Also consider whether it is important to enforce a specific set of actions leading up to the goal, or whether the actions matter less than the goal.
- Encourage people to follow patterns of action that are important: This involves creating incentives to encourage people to carry out certain important actions in specified ways. It is not enough to design and implement a particular pattern within a routine. One has to make it worthwhile for people to follow it.
- Make it possible for users to become designers: Most routines involve decisions points where actors have to choose between alternate, but fixed, courses of action. At such points human actors have little room to improvise. Instead, it may be more fruitful to replace decision points with design points, where actors improvise their actions.
- Lock in actions that matter: Notwithstanding the previous point, there are certain actions that absolutely must be executed as designed. It is as important to ensure that these are executed as they should be as it is to allow people to improvise in other situations.
- Keepan open mind and invite engagement: Perhaps the most important point is to continually engage with people who work the routine and to be open to their input as to what’s working and what isn’t.
Most of the above points are not new; I’d even go so far as to say they are obvious. Nevertheless they are worth restating because they are often unheeded.
Conclusion
A paradox of enterprise systems is that they can fail even if built according to specification. When this happens it is usually because designers fail to appreciate the flexibility of the business process(es) in question. As the authors state, “…even today, organizational routines are widely misunderstood as rigid, mundane, mindless, and explicitly stored somewhere.” This is particularly true for processes that involve humans. As the authors put it, when automating processes that involve humans it is a mistake to design software artefacts while hoping for (fixed) patterns of action. The tragedy is that this is exactly how enterprise systems are often designed.
An ABSERD incident – a service desk satire
The expenses application crashed just as Tina had finished entering the last line. She wasn’t duly alarmed; this had happened to her a couple of times before, but Nathan in IT was able to sort it out without her having to reenter her expenses.
She dialled his number, he answered in a couple of rings. After a brief exchange of pleasantries, she described the problem.
To her surprise, he replied, “I’m sorry Tina, I can’t help you. You will have to call the service desk.”
“The service desk?” She asked, “What’s that?”
“We have streamlined our IT service procedures to comply with the ABSERD standard – which stands for Absolutely Brilliant SERvice Desks. It is an ABSERD requirement that all service calls must be routed through a centralised service desk.” explained Nate. “The procedures and the numbers you need to call were in the email that was sent out to everyone last week.”
“Yes, I read it, but I didn’t think the ABSERD procedures applied to something like the expenses app.,” said Tina, somewhat bemused.
“I’m afraid it applies to all services that IT offers,” said Nate.
“But isn’t the service desk located elsewhere? Will they even know what the expenses app is let alone how to fix it?”
“Ummm…they’ll fix it if they can and escalate it to the next level if they can’t,” replied Nate. “The ABSERD processes are detailed in the email,” he explained again helpfully.
“You know what the problem is. Tell me honestly: do you think they’ll be able to fix it?”
“Probably not,” admitted Nate.
“So they’ll escalate it. How long will that take?”
“The ABSERD service level agreement specifies that all non-critical issues will be responded to within 48 hours. I’m afraid the expenses app is classified as non-critical.”
“So that’s 48 hours to fix an issue that you could sort out in minutes,” stated Tina in a matter of fact tone.
“Ummm…no, it’s 48 hours to respond. That’s the time frame in which they will fix the issue if they can or escalate it if they can’t fix it. As I mentioned, in this case they’ll probably have to escalate” clarified Nate.
“You mean they’ll take 48 hours to figure out they can’t do it. Now, that is truly absurd!” Tina was seriously annoyed now.
“Well, the service desk deals with calls from the entire organisation. They have to prioritise them somehow and this is the fairest way to do it,” said Nate defensively. “Moreover, the service level agreement specifies 48 hours, but there’s a good chance you’ll get a response within a day,” he added in an attempt to placate her.
“And who will they escalate the call to after 48 (or 24) hours if they can’t fix it?” asked Tina exasperatedly.
“Ummm….that would be me,” said Nate sheepishly.
“I’m sorry, but I’m totally lost now. By your own admission, you’ll probably be the one to fix this problem. So why can’t you just do it for me?”
“I’d love to, Tina” said Nate, “but I can’t. Jim will have my hide if he knows that I have bypassed the ABSERD process. I’m sorry, you’re just going to have to call or email the service desk. I can’t do anything about it”
“Why are we suddenly following this ABSERD process anyway? What’s the aim of it all?” asked Tina.
“Well, our aim is to improve the quality of our service. The ABSERD standard is a best practice for IT service providers…,” he trailed off, realising that he sounded like a commercial for ABSERDity.
“You do agree that it actually increases the service time for me. You could have fixed the issue for me in the time we’ve had this conversation but I’m going to have to wait at least 24 hours. I fail to see what has “improved” here.”
“Look, this is the new process. I’m sorry can’t do anything about it,” said Nate lamely.
“OK, I’ll log the call.” she said resignedly.
“I’m sorry, Tina. I really am.”
“It’s not your fault,” she said in a gentler tone, “but I’m probably going to miss the deadline for getting my expenses in this month.”
“Tell you what,” said Nate, as the obvious solution dawned on him, “I’ll fix the problem now… but please log the call just in case someone checks.”
“Are you sure you can do that?” asked Tina. “It would be nice to get reimbursed this month, but I do not want you to get into trouble.”
“It shouldn’t be a problem as long as you don’t tell anyone about it…I wouldn’t want to make it known that I bypass the ABSERD procedures as a matter of course.”
“My lips are sealed,” said Tina. “Thanks Nate, I really appreciate your help with this.”
“No worries Tina. I’ll call you when it’s done,” he said as he ended the call.
Dark clouds, silver linings: a transaction cost perspective on the outsourcing of information systems
Introduction
Some years ago, I wrote a post applying ideas of transaction cost economics to the question of outsourcing IT development work. In that post I argued that evaluating costs on the basis of vendor quotes alone is highly misleading. One has to also factor in transaction costs – i.e. costs relating to things such as search, bargaining and contract enforcement.
In the present post I discuss transaction cost theory as it applies to the question of whether or not organisations should outsource their enterprise systems (such as ERP and CRM applications) to Software as a Service (SaaS) vendor. With the increasing number of offerings on the market, this issue is one that is high on the agenda of IT decision makers.
To be sure, there are many well-known (and massively hyped!) benefits of cloud-based solutions. To name just one: organisations that take the SaaS route do not have to worry about maintenance, upgrades etc. as these are handled by the vendor. As we shall see, however, when it comes to costs, things are not so clear.
Setting the context
Today’s IT landscape is considerably more complex than that of a couple of decades ago. Improvements in infrastructural technology now offer the IT decision maker choices that were simply not available then. One of the basic choices a decision maker is faced when implementing a new enterprise system is whether to develop (or customize), host and support it in-house or opt for a cloud-based offering. Most often decisions on these matters are made on the basis of vendor-quoted costs alone. A typical discussion between a supporter and skeptic of outsourcing may go as follows:
Supporter: We should outsource our CRM system because we will save costs. We can save X million dollars on licensing and hardware…and then there are potential savings on personnel costs in the longer term.
Skeptic: Yes, but we lose flexibility to modify the application to suit our needs.
Supporter: Flexibility is overrated. We have done a gap-fit analysis and have found that most of core business needs can be satisfied by the three shortlisted cloud offerings. We are not a complex business: we call on customers, sell them our product and then follow-up from time to time to see how they are going and whether there are potential opportunities to sell them upgrades. It’s pretty much what everyone else in the business does.
Skeptic: What about vendor lock-in?
Supporter: There is no lock in we pay as we go; per user per month.
….and so the conversation goes. The supporter seems to have an answer for every question so the skeptic may eventually concede. However, the latter may still be left with a vague sense of unease that something’s been overlooked, and indeed something has…which brings us to the next topic.
Transaction costs
A firm has two choices for any economic activity: performing the activity in-house or going to market. In either case, the cost of the activity can be decomposed into:
- Production costs, which are direct (easily quantifiable) costs of producing the good or service
- Transaction costs, which are other (indirect) costs incurred in performing the economic activity.
Production costs include things such as per user cost etc. These are typically quoted upfront and are easy to contractualise (i.e. put into a contract). Things are more complicated when it comes to transactions costs. To see this, let’s take a quick look at the different types of transaction costs:
- Search /selection costs: These are the costs associated with searching for and shortlisting vendors.
- Bargaining costs: These are costs associated with negotiations for a mutually acceptable contract.
- Maintenance costs: These are expected costs (i.e. those that were foreseen when the contract drawn up) associated with ongoing support, enhancements or upgrades.
- Costs of enforcement and change: These are costs associated with enforcing the terms of the contract and those associated with change.
These costs are typically hard to estimate upfront, and nearly impossible to contractualise. Moreover, in most cases, they are largely borne by the client.
Dark clouds
The difficulties associated with contractualising transaction costs arise from the following:
- Unexpected events: Unforeseen and unforeseeable changes in the customer / vendor organisations or in the business environment may entail major changes in the application functionality or even the outsourcing arrangement.
- Bounded rationality: Business environments are complex and it is impossible for the human mind to anticipate everything that can possibly occur. As a consequence, every contract is necessarily incomplete; there is bound to be something that is overlooked. It is impossible contractualise every eventuality.
- Strategic / opportunistic behaviour: the vendor or customer may deliberately withold certain information from the other party at the outset in order to secure the contract at a favourable rate. Typical vendor behaviour may include not revealing certain limitations of the software on the other hand, the customer may attempt to include unfair penalty clauses into the contract or squeeze the vendor on margins.
Now before I’m accused of being unduly alarmist I should mention that certain kinds of enterprise systems are not subject to the above difficulties, or at least not significantly. Typically these are infrastructural services such as servers, operating systems, databases and even simple, context-independent applications such as email. These can be outsourced successfully without any problems because the services to be provided can be specified accurately upfront and thus contractualised unambiguously.
However, for enterprise applications such as ERP and CRM the situation is different because these systems are more or less unique to a given organisation – in other words, they are context-dependent. Their uniqueness renders them vulnerable to the points mentioned above because it is impossible to foresee all possibilities. As a consequence it is inevitable that any outsourcing deal involving such systems will eventually be affected by one or more of the above uncertainties.
Silver linings
None of the above points is new: both vendors and customers are at least somewhat aware that application outsourcing deals have many unknowns. Consequently, both parties try to minimise their exposure to uncertainty. Unfortunately, they usually go about this in exactly the wrong way: they attempt to build safety for themselves at the cost of the other party. They do this by attempting to contractualise all possible things that can go wrong from their point of view. This is impossible because the future cannot be predicted. Contracts, however detailed, will necessarily be incomplete.
The way out is simple. As Oliver Williamson, winner of the 2009 Economics Nobel Prize, tells us:
…important to the transaction-cost economics enterprise is the assumption that contracts, albeit incomplete, are interpreted in a farsighted manner, according to which economic actors look ahead, perceive potential hazards and embed transactions in governance structures that have hazard-mitigating purpose and effect. Also, most of the governance action works through private ordering with courts being reserved for purposes of ultimate appeal.
As he tells us, contracts need to be interpreted in a farsighted manner and governance action should work through private ordering (directly between the customer and vendor). Essentially, the success of an outsourcing deal is to a large extent the joint responsibility of the customer and vendor. Above all, it calls for a relationship based on old-fashioned notion of trust.
Interestingly, Elinor Ostrom, who jointly won the 2009 Economics Nobel with Williamson, had much to say about informal contracts, private ordering and trust. Her extensive studies on collectives lead her to conclude that successful collective endeavours have the following two elements in common:
- High levels of face-to-face communication
- Innovative governance structures that are designed and enforced by the participants rather than external authorities.
The relevance of these to an outsourcing arrangement is clear: face to face communication builds trust, and innovative internal governance structures that are enforceable without legal recourse will discourage opportunistic behaviour from both parties. Although the latter may sound a bit utopian there are proven ways to set up such governance structures (see this paper for an example).
Conclusion
In this post I have argued that a proper analysis of SaaS deals must include transaction costs. Although these are difficult to quantify, a consideration of the different categories of transaction costs will at least lead to a more realistic appraisal of such arrangements. It is my belief that many outsourcing deals go sour because transaction costs are overlooked. Given that it is impossible to foresee the future, the best course of action is to develop a business relationship that is based on trust.
To sum up: most important factor in enterprise application outsourcing is not cost, but trust – an ineffable element that can neither be quantified nor contractualised.


