Archive for the ‘Monte Carlo Simulation’ Category
The drunkard’s dartboard: an intuitive explanation of Monte Carlo methods
(Note to the reader: An Excel sheet showing sample calculations and plots discussed in this post can be downloaded here.)
Monte Carlo simulation techniques have been applied to areas ranging from physics to project management. In earlier posts, I discussed how these methods can be used to simulate project task durations (see this post and this one for example). In those articles, I described simulation procedures in enough detail for readers to be able to reproduce the calculations for themselves. However, as my friend Paul Culmsee mentioned, the mathematics tends to obscure the rationale behind the technique. Indeed, at first sight it seems somewhat paradoxical that one can get accurate answers via random numbers. In this post, I illustrate the basic idea behind Monte Carlo methods through an example that involves nothing more complicated than squares and circles. To begin with, however, I’ll start with something even simpler – a drunken darts player.
Consider a sozzled soul who is throwing darts at a board situated some distance from him. To keep things simple, we’ll assume the following:
- The board is modeled by the circle shown in Figure 1, and our souse scores a point if the dart falls within the circle.
- The dart board is inscribed in a square with sides 1 unit long as shown in the figure, and we’ll assume for simplicity that the dart always falls somewhere within the square (our protagonist is not that smashed).
- Given his state, our hero’s aim is not quite what it should be – his darts fall anywhere within the square with equal probability. (Note added on 01 March 2011: See the comment by George Gkotsis below for a critique of this assumption)

Figure 1: "Dartboard" and enclosing square
We can simulate the results of our protagonist’s unsteady attempts by generating two sets of uniformly distributed random numbers lying between 0 and 1 (This is easily done in Excel using the rand() function). The pairs of random numbers thus generated – one from each set – can be treated as the (x,y) coordinates of the dart for a particular throw. The result of 1000 pairs of random numbers thus generated (representing the drunkard’s dart throwing attempts) is shown in Figure 2 (For those interested in seeing the details, an Excel sheet showing the calculations for 100o trials can be downloaded here).

Figure 2: Result for 1000 throws
A trial results in a “hit” if it lies within the circle. That is, if it satisfies the following equation:

(Note: if we replace “<” by “=” in the above expression, we get the equation for a circle of radius 0.5 units, centered at x=0.5 and y=0.5.)
Now, according to the frequency interpretation of probability, the probability of the plastered player scoring a point is approximated by the ratio of the number of hits in the circle to the total number of attempts. In this case, I get an average of 790/1000 which is 0.79 (generated from 10 sets of 1000 trials each). Your result will be different from because you will generate different sets of random numbers from the ones I did. However, it should be reasonably close to my result.
Further, the frequency interpretation of probability tells us that the approximation becomes more accurate as the number of trials increases. To see why this is so, let’s increase the number of trials and plot the results. I carried out simulations for 2000, 4000, 8000 and 16000 trials. The results of these simulations are shown in Figures 3 through 6.

Figure 3: Result for 2000 throws

Figure 4: Result for 4000 throws

Figure 5: Result for 8000 throws

Figure 6: Result for 16000 throws
Since a dart is equally likely to end up anywhere within the square, the exact probability of a hit is simply the area of the dartboard (i.e. the circle) divided by the entire area over which the dart can land. In this case, since the area of the enclosure (where the dart must fall) is 1 square unit, the area of the dartboard is actually equal to the probability. This is easily seen by calculating the area of the circle using the standard formula 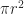

As we see from Figure 6, in the 16000 trial case, the entire square is peppered with closely-spaced “dart marks” – so much so, that it looks as though the square is a uniform blue. Hence, it seems intuitively clear that as we increase, the number of throws, we should get a better approximation of the area and, hence, the probability.
There are a couple of points worth mentioning here. First, in principle this technique can be used to calculate areas of figures of any shape. However, the more irregular the figure, the worse the approximation – simply because it becomes less likely that the entire figure will be sampled correctly by “dart throws.” Second, the reader may have noted that although the 16000 trial case gives a good enough result for the area of the circle, it isn’t particularly accurate considering the large number of trials. Indeed, it is known that the “dart approximation” is not a very good way of calculating areas – see this note for more on this point.
Finally, let’s look at connection between the general approach used in Monte Carlo techniques and the example discussed above (I use the steps described in the Wikipedia article on Monte Carlo methods as representative of the general approach):
- Define a domain of possible inputs – in our case the domain of inputs is defined by the enclosing square of side 1 unit.
- Generate inputs randomly from the domain using a certain specified probability distribution – in our example the probability distribution is a pair of independent, uniformly distributed random numbers lying between 0 and 1.
- Perform a computation using the inputs – this is the calculation that determines whether or not a particular trial is a hit or not (i.e. if the x,y coordinates obey inequality (1) it is a hit, else it’s a miss)
- Aggregate the results of the individual computations into the final result – This corresponds to the calculation of the probability (or equivalently, the area of the circle) by aggregating the number of hits for each set of trials.
To summarise: Monte Carlo algorithms generate random variables (such as probability) according to pre-specified distributions. In most practical applications one will use more efficient techniques to sample the distribution (rather than the naïve method I’ve used here.) However, the basic idea is as simple as playing drunkard’s darts.
Acknowledgements
Thanks go out to Vlado Bokan for helpful conversations while this post was being written and to Paul Culmsee for getting me thinking about a simple way to explain Monte Carlo methods.
Monte Carlo simulation of risk and uncertainty in project tasks
Introduction
When developing duration estimates for a project task, it is useful to make a distinction between the uncertainty inherent in the task and uncertainty due to known risks. The former is uncertainty due to factors that are not known whereas the latter corresponds uncertainty due to events that are known, but may or may not occur. In this post, I illustrate how the two types of uncertainty can be combined via Monte Carlo simulation. Readers may find it helpful to keep my introduction to Monte Carlo simulations of project tasks handy, as I refer to it extensively in the present piece.
Setting the stage
Let’s assume that there’s a task that needs doing, and the person who is going to do it reckons it will take between 2 and 8 hours to complete it, with a most likely completion time of 4 hours. How the estimator comes up with these numbers isn’t important here – maybe there’s some guesswork, maybe some padding or maybe it is really based on experience (as it should be). For simplicity we’ll assume the probability distribution for the task duration is triangular. It is not hard to show that, given the above mentioned estimates, the probability, 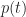

And,
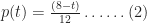
These two expressions are sometimes referred to as the probability distribution function (PDF). The PDF described by equations (1) and (2) is illustrated in Figure 1. (Note: Please click on the Figures to view full-size images)

Figure 1: Probability distribution for task
Now, a PDF tells us the probability that the task will finish at a particular time 

and,

For a detailed derivation, please see my introductory post. The CDF for the distribution is shown in Figure 2.

Figure 2: CDF for task
Now for the complicating factor: let us assume there is a risk that has a bearing on this task. The risk could be any known factor that has a negative impact on task duration. For example, it could be that a required resource is delayed or that the deliverable will fails a quality check and needs rework. The consequence of the risk – should it eventuate – is that the task takes longer. How much longer the task takes depends on specifics of the risk. For the purpose of this example we’ll assume that the additional time taken is also described by a triangular distribution with a minimum, most likely and maximum time of 1, 2 and 3 hrs respectively. The PDF 

And

The figure for this distribution is shown in Figure 3.

Figure 3: Probability distribution of additional time due to risk
The CDF for the additional time taken if the risk eventuates (which we’ll denote by 

and,
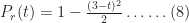
The CDF for the risk consequence is shown in Figure 4.

Figure 4: CDF of additional time due to risk
Before proceeding with the simulation it is worth clarifying what all this means, and what we want to do with it.
Firstly, equations 1-4 describe the inherent uncertainty associated with the task while equations 5 through 8 describe the consequences of the risk, if it eventuates.
Secondly, we have described the task and the risk separately. In reality, we need a unified description of the two – a combined distribution function for the uncertainty associated with the task and the risk taken together. This is what the simulation will give us.
Finally, one thing I have not yet specified is the probabilty that the risk will actually occur. Clearly, the higher the probability, the greater the potential delay. Below I carry out simulations for risk probabilities of varying from 0.1 to 0.5.
That completes the specification of the problem – let’s move on to the simulation.
The simulation
The simulation procedure I used for the zero-risk case (i.e. the task described by equations 1 and 2 ) is as follows :
- Generate a random number between 0 and 1. Treat this number as the cumulative probability,
- Find the time,
- Repeat steps (1) and (2) for a sufficiently large number of trials.
The frequency distribution of completion times for the task, based on 30,000 trials is shown in Figure 5.

Figure 5: Simulation histogram for zero-risk case
As we might expect, Figure 5 can be translated to the probability distribution shown in Figure 1 by a straightforward normalization – i.e. by dividing each bar by the total number of trials.
What remains to be done is to incorporate the risk (as modeled in equations 5-6) into the simulation. To simulate the task with the risk, we simply do the following for each trial:
- Simulate the task without the risk as described earlier.
- Generate another random number between 0 and 1.
- If the random number is less than the probability of the risk, then simulate the risk. Note that since the risk is described by a triangular function, the procedure to simulate it is the same as that for the task (albeit with different parameters).
- If the random number is greater than the probability of the risk, do nothing.
- Add the results of 1 and 4. This is the outcome of the trial.
- Repeat steps 1-5 for as many trials as required.
I performed simulations for the task with risk probabilities of 10%, 30% and 50%. The frequency distributions of completion times for these are displayed in Figures 6-8 (in increasing order of probability). As one would expect, the spread of times increases with increasing probability. Further, the distribution takes on a distinct second peak as the probability increases: the first peak is at 


Figure 6: Simulation histogram (10% probability of risk)

Figure 7: Simulation histogram (30% probability of risk)

Figure 8: Frequency histogram (50% probability of risk)
It is also instructive to compare average completion times for the four cases (zero-risk and 10%, 30% and 50%). The average can computed from the simulation by simply adding up the simulated completion times (for all trials) and dividing by the total number of simulation trials (30,000 in our case). On doing this, I get the following:
Average completion time for zero-risk case = 4.66 hr
Average completion time with 10% probability of risk = 4.89 hrs
Average completion time with 30% probability of risk = 5.36 hrs
Average completion time with 50% probability of risk= 5.83 hrs
No surprises here.
One point to note is that the result obtained from the simulation for the zero-risk case compares well with the exact formula for a triangular distribution (see the Wikipedia article for the triangular distribution):

This serves as a sanity check on the simulation procedure.
It is also interesting to compare the cumulative probabilities of completion in the zero-risk and high risk (50% probability) case. The CDFs for the two are shown in Figure 9. The co-plotted CDFs allow for a quick comparison of completion time predictions. For example, in the zero-risk case, there is about a 90% chance that the task will be completed in a little over 6 hrs whereas when the probability of the risk is 50%, the 90% completion time increases to 8 hrs (see Figure 9).

Figure 9: CDFs for zero risk and 50% probability of risk cases
Next steps and wrap up
For those who want to learn more about simulating project uncertainty and risk, I can recommend the UK MOD paper – Three Point Estimates And Quantitative Risk Analysis A Process Guide For Risk Practitioners. The paper provides useful advice on how three point estimates for project variables should be constructed. It also has a good discussion of risk and how it should be combined with the inherent uncertainty associated with a variable. Indeed, the example I have described above was inspired by the paper’s discussion of uncertainty and risk.
Of course, as with any quantitative predictions of project variables, the numbers are only as reliable as the assumptions that go into them, the main assumption here being the three point estimates that were used to derive the distributions for the task uncertainty and risk (equations 1-2 and 5-6). Typically these are obtained from historical data. However, there are well known problems associated with history-based estimates. For one, as we can never be sure that the historical tasks are similar to the one at hand in ways that matter (this is the reference class problem). As Shim Marom warns us in this post, all our predictions depend on the credibility of our estimates. Quoting from his post:
Can you get credible three point estimates? Do you have access to credible historical data to support that? Do you have access to Subject Matter Experts (SMEs) who can assist in getting these credible estimates?
If not, don’t bother using Monte Carlo.
In closing, I hope my readers will find this simple example useful in understanding how uncertainty and risk can be accounted for using Monte Carlo simulations. In the end, though, one should always keep in mind that the use of sophisticated techniques does not magically render one immune to the GIGO principle.
The reference class problem and its implications for project management
Introduction
Managers make decisions based on incomplete information, so it is no surprise that the tools of probability and statistics have made their way into management practice. This trend has accelerated somewhat over the last few years, particularly with the availability of software tools that simplify much of the grunt-work of using probabilistic techniques such as Monte Carlo methods or Bayesian networks. Purveyors of tools and methodologies and assume probabilities (or more correctly, probability distributions) to be known, or exhort users to determine probabilities using relevant historical data. The word relevant is important: it emphasises that the data used to calculate probabilities (or distributions) should be from situations that are similar to the one at hand. This innocuous statement papers over a fundamental problem in the foundations of probability: the reference class problem. This post is a brief introduction to the reference class problem and its implications for project management.
I’ll begin with some background and then, after defining the problem, I’ll present a couple of illustrations of the problem drawn from project management.
Background and the Problem
The most commonly held interpretation of probability is that it is a measure of the frequency with which an event of interest occurs. In this frequentist view, as it is called, probability is defined as the ratio of the number of times the event of interest occurs to the total number of events. An example might help clarify what this means: the probability that a specific project will finish on time is given by the ratio of the number of similar projects that have finished on time to the total number of similar projects undertaken (including both on-time and not-on-time projects).
At first sight the frequentist approach seems a reasonable one. However, in this straightforward definition of probability lurks a problem: how do we determine which events are similar to the one at hand? In terms of the example: what are the criteria by which we can determine the projects that resemble the one we’re interested in? Do we look at projects with similar scope, or do we use size (in terms of budget, resources or other measure), or technology or….? There could be a range of criteria that one could use, but one never knows with certainty which one(s) is (are) the right one(s). Why is it an issue? It’s an issue because probability changes depending on the classification criteria used. This is the reference class problem.
In a paper entitled The Reference Class Problem is Your Problem Too, the philosopher Alan Hajek sums it up as follows:
The reference class problem arises when we want to assign a probability to a proposition (or sentence, or event) X, which may be classified in various ways, yet its probability can change depending on how it is classified.
Incidentally, in another paper entitled Conditional Probability is the Very Guide of Life, Hajek discusses how the reference class problem afflicts all major interpretations of probability, not just the frequentist approach. We’ll stick with the latter interpretation since it is the one used in project management practice and research… and virtually all the social and natural sciences to boot.
The reference class problem in project management
Let’s look at a couple of project management-related illustrations of the reference class problem.
First up, consider the technique of reference class forecasting which I’ve discussed in this post. Note that reference class forecasting technique is distinct from the reference class problem although, as we shall see in less than a minute, the technique is fatally afflicted by the problem.
What’s reference class forecasting? To quote from the post referenced earlier, the technique involves:
…creating a probability distribution of estimates based on data for completed projects that are similar to the one of interest, and then comparing the said project with the distribution in order to get a most likely outcome. Basically, [it] consists of the following steps:
- Collecting data for a number of similar past projects – these projects form the reference class. The reference class must encompass a sufficient number of projects to produce a meaningful statistical distribution, but individual projects must be similar to the project of interest.
- Establishing a probability distribution based on (reliable!) data for the reference class. The challenge here is to get good data for a sufficient number of reference class projects.
- Predicting most likely outcomes for the project of interest based on comparisons with the reference class distribution.
Now, the key assumption in reference class forecasting is that it is possible to identify a number of completed projects that are similar to the one at hand. But what does “similar” mean? Clearly the composition of the reference class depends on the similarity criteria used, and consequently so does the resulting distribution. Reference class forecasting is a victim of the reference class problem!
The reference class problem will affect any technique that uses arbitrary criteria to determine the set of all possible events. As another example, the probability distributions used in Monte Carlo simulations (of project cost, duration or whatever) are determined using historical data. Again, typically one selects projects (or tasks – if one is doing a task level simulation) that are similar to the one at hand. Defining “similar” is left to common sense or expert judgement or some other subjective approach. Yet, by the most commonly used definition, a project is a “temporary endeavor, having a defined beginning and end, undertaken to meet unique goals and objectives”. By definition, therefore, we never do the same project twice – at best we do the same project differently (and the same applies to tasks). So, despite ones best intentions and efforts, historical data can never be totally congruent to the situation at hand. There will always be differences, and one cannot tell with certainty that those differences do not matter.
Truth be told, most organizations do not retain data on completed projects – except superficial stuff that isn’t much use. The reference class problem seems to justify the position of this slack majority. After all, why bother keeping data when one isn’t able to use it to predict project performance. This argument is wrong-headed: although one cannot use it to calculate probabilities, historical data is useful because it keeps us from repeating our errors. Just don’t expect the data to yield reliable quantitative information on probabilities.
Before I close this piece, I should clarify that there are areas in which the reference class problem is not an issue. In physics, for example, the discipline of statistical mechanics is founded on the principle that the average motion of large collections of molecules can be treated statistically. Clearly, there is no problem here: molecules are indeed indistinguishable from each other, so it is clear that a particular molecule (of a gas in a container of carbon dioxide, say) belongs to the reference class of all carbon dioxide molecules in that container. In general this is true of any situation where one is dealing with a large collection of identical (or very similar) entities.
Conclusion
The reference class problem affects most probabilistic methods in project management and other areas of the social sciences. It is a problem because it is often impossible to know beforehand which attributes of the objects or events of interest are the most significant ones. Consequently it is impossible to determine with certainty whether or not a particular object or event belongs to a defined reference class.
I’ll end with an anecdote to illustrate my point:
Some time ago I was asked to provide estimates for design work that was superficially similar to something I’d done before. “You’ve done this before,” a manager said, “so you should be able to estimate this quite accurately.”
As many best practices and methodologies recommend, I used a mix of historical data and “expert” judgement (and added in a dash of padding) to arrive at (what I thought was) a robust estimate. To all you agilists out there, an incremental approach was not an option in this case.
I got it wrong – badly wrong. It turned out that the unique features of the project, which weren’t apparent at first, made a mockery of my estimates. I didn’t know it then, but I’d fallen victim to the reference class problem.
Finally, it should be clear that although my examples are project management focused, the arguments are quite general. They apply to all areas of management theory and practice, and indeed to most areas of inquiry that use probabilistic techniques. To use the words of Alan Hajek: the reference class problem is your problem too.


