Archive for the ‘portfolio management’ Category
An introduction to the critical chain method
Introduction
All project managers have to deal with uncertainty as a part of their daily work. Project schedules, so carefully constructed, are riddled with assumptions and uncertainties – particularly in task durations. Most project management treatises (the PMBOK included) recognise this, and so exhort project managers to include uncertainties in their activity duration estimates. However, the same books have little to say on how these uncertainties should be integrated into the project schedule in a meaningful way. Sure, well-established techniques such as PERT incorporate probabilities into a schedule via an averaged or expected duration, but the final schedule is deterministic – i.e each task is assigned a definite completion date, based on the expected duration. Any float that appears in the schedule is purely a consequence of an activity not being on the critical path. The float, such as it is, is not an allowance for uncertainty.
Since PERT was invented in the 1950s, there have been several other attempts to incorporate uncertainty into project scheduling. Some of these include, Monte Carlo simulation and, more recently, Bayesian Networks. Although these techniques have a more sound basis, they don’t really address the question of how uncertainty is to be managed in a project schedule, where individual tasks are strung together one after another. What’s needed is a simple technique to protect a project schedule from Murphy, Parkinson or any other variations that invariably occur during the execution of individual tasks. In the 1990s, Eliyahu Goldratt proposed just such a technique in his business novel, Critical Chain. This post presents a short, yet comprehensive introduction to Goldratt’s critical chain method .
[An Aside: Before proceeding any further I should mention that Goldratt formulated the critical chain method within the framework of his Theory of Constraints (TOC). I won’t discuss TOC in this article, mainly because of space limitations. Moreover, an understanding of TOC isn’t really needed to understand the critical chain method. For those interested in learning about TOC, the best starting point is Goldratt’s business novel, The Goal.]
I begin with a discussion of some general characteristics of activity or task estimates, highlighting the reason why task estimators tend to pad up their estimates. This is followed by a discussion on why the buffers (or safety) that estimators build into individual activities don’t help – i.e. why projects come in late despite the fact that most people add considerable safety factors on to their activity estimates. This then naturally leads on to the heart of the matter: how buffers should be added in order to protect schedules effectively.
Characteristics of activity duration estimates
(Note: Portions of this section have been published previously in my post on the inherent uncertainty of project task estimates)
Consider an activity that you do regularly – such as getting ready in the morning. You have a pretty good idea how long the activity takes on average. Say, it takes you an hour on average to get ready – from when you get out of bed to when you walk out of your front door. Clearly, on a particular day you could be super-quick and finish in 45 minutes, or even 40 minutes. However, there’s a lower limit to the early finish – you can’t get ready in 0 minutes!. On the other hand, there’s really no upper limit. On a bad day you could take a few hours. Or if you slip in the shower and hurt your back, you mayn’t make it at all.
If we were to plot the probability of activity completion for this example as a function of time, it might look something like I’ve depicted in Figure 1. The distribution starts at a non-zero cutoff (corresponding to the minimum time for the activity); increases to a maximum (corresponding to the most probable time); and then falls off rapidly at first, then with a long, slowly decaying, tail. The mean (or average) of the distribution is located to the right of the maximum because of the long tail. In the example, 

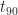
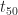

It turns out that many phenomena can be modeled by this kind of long-tailed distribution. Some of the better known long-tailed distributions include lognormal and power law distributions. A quick (but admittedly informal) review of the project management literature revealed that lognormal distributions are more commonly used than power laws to model activity duration uncertainties. This may be because lognormal distributions have a finite mean and variance whereas power law distributions can have infinite values for both (see this presentation by Michael Mitzenmacher, for example). [An Aside:If you’re curious as to why infinities are possible in the latter, it is because power laws decay more slowly than lognormal distributions – i.e they have “fatter” tails, and hence enclose larger (even infinite) areas.]. In any case, regardless of the exact form of the distribution for activity estimates, what’s important and non-controversial is the short cutoff, the peak and long, decaying tail.
Most activity estimators are intuitively aware of the consequences of the long tail. They therefore add a fair amount of “air” or safety in their estimates. Goldratt suggests that typical activity estimates tend to correspond to
Delays accumulate; gains don’t
A schedule is essentially made up of several activities (of varying complexity and duration) connnected sequentially or in parallel. What are the implications of uncertain activity durations on a project schedule? Well, let’s look at the case of sequential and parallel steps separately:
Sequential steps: If an activity finishes early, the successor activity rarely starts right away. More often, the successor activity starts only when it was originally scheduled to. Usually this happens because the resource responsible for the successor activity is not free – or hasn’t been told about the early finish of the predecessor activity. On the other hand, if an activity finishes late, the start of the successor activity is delayed by at least the same amount as the delay. The upshot of all this is that – delays accumulate but early finishes are rarely taken advantage of. So, in a long chain of sequential activities, you can be pretty sure that there will be delays.
Parallel steps: In this case, the longest duration activity dictates the finish time. For example, if we have three parallel activities that take 5 days each. If one of them ends up taking 10 days, the net effect is that three activities, taken together, will complete only after 10 days. In contrast, an early finish will not have an effect unless all activities finish early (and by the same amount!). Again we see that delays accumulate; early finishes don’t.
The above discussion assumed that activities are independent. In a real project activities can be highly dependent. In general this tends to make things worse – a delay in an activity is usually magnified by a dependent successor activity.
This partially explains why projects come in late. However it’s not the whole story. According to Goldratt, there are a few other factors that lead to dissipation of safety. I discuss these next.
Other time wasters
In the previous section we saw that dependencies between activities can eat into safety significantly because delays accumulate while gains don’t. There are a couple of other ways safety is wasted. These are:
Multitasking It is recognised that multitasking – i.e. working on more than one task concurrently – introduces major delays in completing tasks. See these articles by Johanna Rothman and Joel Spolsky, for a discussion of why this is so. I’ve discussed techniques to manage multitasking in an earlier post.
Student syndrome This should be familiar to any one who’s been a student. When saddled with an assignment, the common tendency is to procrastinate until the last moment. This happens on projects as well. “Ah, there’s so much time. I’ll start later…” Until, of course, there isn’t very much time at all.
Parkinson’s Law states that “work expands to fill the allocated time.” This is most often a consequence of there being no incentive to finish a task early. In fact, there’s a strong disincentive from finishing early because the early finisher may be a) accused of overestimating the task or b) rewarded by being allocated more work. Consequently people tend to adjust their pace of work to just make the scheduled delivery date, thereby making the schedule a self-fulfilling prophecy.
Any effective project management system must address and resolve the above issues. The critical chain method does just that. Now with the groundwork in place, we can move on to a discussion of the technique. We’ll do this in two steps. First, we discuss the special case in which there is no resource contention – i.e. multitasking does not occur. The second, more general, case discusses the situation in which there is resource contention.
The critical chain – special case
In this section we look at the case where there’s no resource contention in the project schedule. In this (ideal) situation, where every resource is available when required, each task performer is ready to start work on a specific task just as soon as all its predecessor tasks are complete. Sure, we’ll also need to put in place a process to notify successor task performers about when they need to be ready to start work, but I’ll discuss this notification process a little later in this section. Let’s tackle Parkinson and the procrastinators first.
Preventing the student syndrome and Parkinson’s Law
To cure habitual procrastinators and followers of Parkinson, Goldratt suggests that project task durations estimates be based on a 50% probability of completion. This corresponds to an estimate that is equal to
As discussed earlier, a
- Removal of individual activity completion dates from the schedule altogether. The only important date is the project completion date.
- No penalties for going over the
The above points should be explained clearly to project team members before attempting to elicit
So, how does one get reliable
- Assume that the initial estimates obtained from team members are
- Another option is to ask the estimator how long a task is going to take. They’ll come back to you with a number. This is likely to be their
- Yet another option is to calibrate estimators’ abilities to predict task durations based on their history (i.e. based on how good earlier estimates were). In the absence of prior data one can quantify an estimator’s reliability in making judgements by asking him or her to answer a series of trivia questions, giving an estimated probability of being correct along with each answer. An individual is said to be calibrated if the fraction of questions correctly answered coincides (or is close to) their stated probability estimates. In theory, a calibrated individual’s duration estimate should be pretty good. However, it is questionable as to whether calibration as determined through trivia questions carries over to real-world estimates. See this site for more on evaluating calibration.
- Finally, project managers can use Monte Carlo simulations to estimate task durations. The hard part here is coming up with a probability distribution for the task duration. One commonly used approach is to ask task estimators to come up with best case, worst case and most likely estimates, and then fit these to a probability distribution. There are at least two problems with this approach: a) the only sensible fit to a three point estimate is a triangular distribution, but this isn’t particularly good because it ignores the long tail and b) the estimates still need to be quality assured through independent checks (historical comparison, for example) or via calibration as discussed above – else the distribution is worthless. See this paper for more on the use of Monte Carlo simulations in project management (Note added on 23 Nov 2009: See my post on Monte Carlo simulations of project task durations for a quick introduction to the technique)
Folks who’ve read my articles on cognitive biases in project management (see this post and this one) may be wondering how these fit in to the above argument. According to Goldratt, most people tend to offer their
Getting team members to come up with reliable
The resource buffer
Readers may have noticed a problem arising from the foregoing discussion of
The project buffer
Alright, so now we’ve reduced activity estimates, removed completion dates for individual tasks and ensured that resources are positioned to pick up tasks when they have to. What remains? Well, the most important bit really – the safety! Since tasks now only have a 50% chance of completion within the estimated time, we need to put safety in somewhere. The question is, where should it go? The answer lies in recognising that the bottleneck (or constraint) in a project is the critical path. Any delay in the critical path necessarily implies a delay in the project. Clearly, we need to add the safety somewhere on the critical path. I hope the earlier discussion has convinced you that adding safety to individual tasks is an exercise in futility. Goldratt’s insight was the following: safety should be added to the end of the critical path as a non-activity buffer. He calls this the project buffer. If any particular activity is delayed, the project manager “borrows” time from the project buffer and adds it on to the offending activity. On the other hand, if an activity finishes early the gain is added to the project buffer. Figure 2 depicts a project network diagram with the project buffer added on to the critical path (C1-C2-C3 in the figure).

What size should the buffer be? As a rule of thumb, Goldratt proposed that the buffer should be 50% of the safety that was removed from the tasks. Essentially this makes the critical path 75% as long as it would have been with the original (
The feeding buffer
As shown in Figure 2 the project buffer protects the critical path. However, delays can occur in non-critical paths as well (A1-A2 and B1-B2 in the figure). If long enough, these delays can affect subsequent critical path. To prevent this from happening, Goldratt suggests adding buffers at points where non-critical paths join the critical path. He terms these feeding buffers.

Figure 3 depicts the same project network diagram as before with feeding buffers added in. Feeding buffers are sized the same way as project buffers are – i.e. based on a fraction of the safety removed from the activities on the relevant (non-critical) path.
The critical chain – a first definition
This completes the discussion of the case where there’s no resource contention. In this special case, the critical chain of the project is identical to the critical path. The activity durations for all tasks are based on t50 estimates, with the project buffer protecting the project from delays. In addition, the feeding buffers protect critical chain activities from delays in non-critical chain activities.
The critical chain – general case
Now for the more general case where there is contention for resources. Resource contention implies that task performers are scheduled to work on multiple tasks simultaneously, at one or more points along the project timeline. Although it is well recognised that multitasking is to be avoided, most algorithms for finding the critical path do not take resource contention into account. The first step, therefore, is to resource level the schedule – i.e ensure that tasks that are to be performed the same resource(s) are scheduled sequentially rather than simultaneously. Typically this changes the critical path from what it would otherwise be. This resource leveled critical path is the critical chain.
The above can be illustrated by modifying the example network shown in Figure 3. Assume tasks C1, B2 and A2 (marked X) are performed by the same resources. The resource leveled critical path thus changes from that shown in Figures 2 and 3 to that shown in Figure 4 (in red). As per the definition above, this is the critical chain. Notice that the feeding buffers change location, as (by definition) these have to be moved to points where non-critical paths merge with the critical path. The location of the project buffer remains unchanged.

Endnote
This completes my introduction to the critical chain method. Before closing, I should mention that there has been some academic controversy regarding the critical chain method. In practice, though, the method seems to work well as evidenced by the number of companies offering consulting and software related to critical chain project scheduling.
I can do no better than to end with a list of online references which I’ve found immensely useful in learning about the method. Here they are, in no particular order:
Critical Chain Scheduling and Buffer Management . . . Getting Out From Between Parkinson’s Rock and Murphy’s Hard Place by Francis Patrick.
Critical Chain: a hands-on project application by Ernst Meijer.
The best place to start, however, is where it all began: Goldratt’s novel, Critical Chain.
(Note: This essay is a revised version of my article on the critical chain, first published in 2007)
Cognitive biases as project meta-risks
Introduction and background
A comment by John Rusk on this post got me thinking about the effects of cognitive biases on the perception and analysis of project risks. A cognitive bias is a human tendency to base a judgement or decision on a flawed perception or understanding of data or events. A recent paper suggests that cognitive biases may have played a role in some high profile project failures. The author of the paper, Barry Shore, contends that the failures were caused by poor decisions which could be traced back to specific biases. A direct implication is that cognitive biases can have a significant negative effect on how project risks are perceived and acted upon. If true, this has consequences for the practice of risk management in projects (and other areas, for that matter). This essay discusses the role of cognitive biases in risk analysis, with a focus on project environments.
Following the pioneering work of Daniel Kahneman and Amos Tversky, there has been a lot of applied research on the role of cognitive biases in various areas of social sciences (see Kahneman’s Nobel Prize lecture for a very readable account of his work on cognitive biases). A lot of this research highlights the fallibility of intuitive decision making. But even judgements ostensibly based on data are subject to cognitive biases. An example of this is when data is misinterpreted to suit the decision-maker’s preconceptions (the so-called confirmation bias). Project risk management is largely about making decisions regarding uncertain events that might impact a project. It involves, among other things, estimating the likelihood of these events occurring and the resulting impact on the project. These estimates and the decisions based on them can be erroneous for a host of reasons. Cognitive biases are an often overlooked, yet universal, cause of error.
Cognitive biases as project meta-risks
So, what role do cognitive biases play in project risk analysis? Many researchers have considered specific cognitive biases as project risks: for example, in this paper, Flyvbjerg describes how the risks posed by optimism bias can be addressed using reference class forecasting (see my post on improving project forecasts for more on this). However, as suggested in the introduction, one can go further. The first point to note is that biases are part and parcel of the mental make up of humans, so any aspect of risk management that involves human judgment is subject to bias. As such, then, cognitive biases may be thought of as meta-risks: risks that affect risk analyses. Second, because they are a part of the mental baggage of all humans, overcoming them involves an understanding of the thought processes that govern decision-making, rather than externally-directed analyses (as in the case of risks). The analyst has to understand how his or her perception of risks may be affected by these meta-risks.
The publicly available research and professional literature on meta-risks in business and organisational contexts is sparse. One relevant reference is a paper by Jack Gray on meta-risks in financial portfolio management. The first few lines of the paper state,
“Meta-risks are qualitative, implicit risks that pass beyond the scope of explicit risks. Most are born out the complex interaction between the behaviour pattern of individuals and those of organizational structures” (italics mine).
Although he doesn’t use the phrase, Gray seems to be referring to cognitive biases – at least in part. This is confirmed by a reading of the paper. It describes, among other things, hubris (which roughly corresponds to the illusion of control) and discounting evidence that conflicts with one’s views (which corresponds to confirmation bias) as meta-risks. From this (admittedly small) sampling of the literature, it seems that the notion of cognitive biases as meta-risks has some precedent.
Next, let’s look at how biases can manifest themselves as meta-risks in a project environment. To keep the discussion manageable, I’ll focus on a small set of biases:
Anchoring: This refers to the tendency of humans to rely on a single piece of information when making a decision. I have seen this manifest itself in task duration estimation – where “estimates plucked out of thin air” by management serve as an anchor for subsequent estimation by the project team. See this post for more on anchoring in project situations. Anchoring is a meta-risk because the over-reliance on a single piece of information about a risk can have an adverse effect on decisions relating to that risk.
Availability: This refers to the tendency of people to base decisions on information that can be easily recalled, neglecting potentially more important information. As an example, a project manager might give undue weight to his or her most recent professional experiences when analysing project risks. Here availability is a meta-risk because it is a barrier to an objective consideration of risks that are not immediately apparent to the analyst.
Representativeness: This refers to the tendency to make judgements based on seemingly representative, known samples . For example, a project team member might base a task estimate based on another (seemingly) similar task, ignoring important differences between the two. Another manifestation of representativeness is when probabilities of events are estimated based on those of comparable, known events. An example of this is the gambler’s fallacy. This is clearly a meta-risk, especially where “expert judgement” is used as a technique to assess risk (Why? Because such judgements are invariably based on comparable tasks that the expert has encountered before.).
Selective perception: This refers to the tendency of individuals to give undue importance to data that supports their own views. Selective perception is a bias that we’re all subject to; we hear what we want to hear, see what we choose to see, and remain deaf and blind to the rest. This is a meta-risk because it results in a skewed (or incomplete) perception of risks.
Loss Aversion: This refers to the tendency of people to give preference to avoiding losses (even small losses) over making gains. In risk analysis this might manifest itself as overcautiousness. Loss aversion is a meta-risk because it might, for instance, result in the assignment of an unreasonably large probability of occurrence to a risk.
A particularly common manifestation of loss aversion in project environments is the sunk cost bias. In situations where significant investments have been made in projects, risk analysts might be biased towards downplaying risks.
Information bias: This is the tendency of some analysts to seek as much data as they can lay their hands on prior to making a decision. The danger here is of being swamped by too much irrelevant information. Data by itself does not improve the quality of decisions (see this post by Tim van Gelder for more on the dangers of data-centrism). Over-reliance on data – especially when there is no way to determine the quality and relevance of data as is often the case – can hinder risk analyses. Information bias is a meta-risk for two reasons already alluded to above; first, the data may not capture important qualitative factors and second, the data may not be relevant to the actual risk.
I could work my way through a few more of the biases listed here, but I think I’ve already made my point: projects encompass a spectrum of organisational and technical situations, so just about any cognitive bias is a potential meta-risk.
Conclusion
Cognitive biases are meta-risks because they can affect decisions pertaining to risks – i.e. they are risks of risk analysis. Shore’s research suggests that the risks posed by these meta-risks are very real; they can cause project failure So, at a practical level, project managers need to understand how cognitive biases could affect their own risk-related judgements (or any other judgements for that matter). The previous section provides illustrations of how selected cognitive biases can affect risk analyses; there are, of course, many more. Listing examples is illustrative, and helps make the point that cognitive biases are meta-risks. However, it is more useful and interesting to understand how biases operate and what we can do to overcome them. As I have mentioned above, overcoming biases requires an understanding of the thought processes through which humans make decisions in the face of uncertainty. Of particular interest is the role of intuition and rational thought in forming judgements, and the common mechanisms that underlie judgement-related cognitive biases. A knowledge and awareness of these mechanisms might help project managers in consciously countering the operation of cognitive biases in their own decision making. I’m currently making some notes on these topics, with the intent of publishing them in a forthcoming essay – please stay tuned.
—
Note
Part II of this post published here.
Cox’s risk matrix theorem and its implications for project risk management
Introduction
One of the standard ways of characterising risk on projects is to use matrices which categorise risks by impact and probability of occurrence. These matrices provide a qualitative risk ranking in categories such as high, medium and low (or colour: red, yellow and green). Such rankings are often used to prioritise and allocate resources to manage risks. There is a widespread belief that the qualitative ranking provided by matrices reflects an underlying quantitative ranking. In a paper entitled, What’s wrong with risk matrices?, Tony Cox shows that the qualitative risk ranking provided by a risk matrix will agree with the quantitative risk ranking only if the matrix is constructed according to certain general principles. This post is devoted to an exposition of these principles and their consequences.
Since the content of this post may seem overly academic to some of my readers, I think it is worth clarifying why I believe an understanding of Cox’s principles is important for project managers. First, 3×3 and 4×4 risk matrices are widely used in managing project risk. Typically these matrices are constructed in an intuitive (but arbitrary) manner. Cox shows – using very general assumptions – that there is only one sensible colouring scheme (or form) of these matrices. This conclusion was surprising to me, and I think that many readers may also find it so. Second, and possibly more important, is that the arguments presented in the paper show that it is impossible to maintain perfect congruence between qualitative (matrix) and quantitative rankings. As I discuss later, this is essentially due to the impossibility of representing quantitative rankings accurately on a rectangular grid. Developing an understanding of these points will enable project managers to use risk matrices in a more logically sound manner.
Background and preliminaries
Let’s begin with some terminology that’s well known to most project managers:
Probability: This is the likelihood that a risk will occur. It is quantified as a number between 0 (will definitely not occur) and 1 (will definitely occur).
Impact (termed “consequence” in the paper): This is the severity of the risk should it occur. It can also be quantified as a number between 0 (lowest severity) and 1(highest severity).
Note that the above scales for probability and impact are arbitrary – other common choices are percentages or a scale of 0 to 10.
Risk: In many project risk management frameworks, risk is characterised by the formula: Risk = probability x impact. This formula looks reasonable, but is typically specified a priori, without any justification.
A risk can be plotted on a two dimensional graph depicting impact (on the x-axis) and probability (on the y-axis). This is typically where the problems start: for most risks, neither the probability nor the impact can be accurately quantified. The standard solution is to use a qualitative scale, where instead of numbers one uses descriptive text – for example, the probability, impact and risk can take on one of three values: high, medium and low (as shown in Figure 1 below). In doing this, analysts make the implicit assumption that the categorisation provided by the qualitative assessment ranks the risks in correct quantitative order. Problem is, this isn’t true.

Figure 1: A 3x3 Risk Matrix
Let’s look at the simple case of two risks A and B ranked on a 2×2 risk matrix shown in Figure 2 below. Let’s assume that the probability and impact of each of the two risks are independent and uniformly distributed between 0 and 1. Clearly, if the two risks have the same qualitative ranking (high, say), there is no way to rank them correctly unless one has quantitative knowledge of probability and impact – which is usually not the case. In the absence of this information, there’s a 50% chance (all other factors being equal) of ranking them correctly – i.e. one is effectively “flipping a coin” to choose which one has the higher (or lower) rank. This situation highlights a shortcoming of risk matrices: poor resolution. It is not possible to rank risks that have the same qualitative ranking.

Figure 2: A 2x2 Risk Matrix
“That’s obvious,” I hear you say – and you’re right. But there’s more: if one of the ratings is medium and the other one is not (i.e. the other one is high or low), then there is a non-zero chance of making an incorrect ranking because some points in the cell with the higher qualitative rating have a lower quantitative value of risk than some points in the cell with the lower qualitative ranking. Look at that statement again: it implies that risk matrices can incorrectly assign higher qualitative rankings to quantitatively smaller risks – i.e. there is the possibility of making ranking errors. This point is seriously counter-intuitive (to me anyway) and merits a proof, which Cox provides and I discuss below. Before doing so, I should also point out that the discussion of this paragraph assumes that the probabilities and impacts of the two risks are independent and uniformly distributed. Cox also points out that the chance of making the wrong ranking can be even higher if the joint distribution of the two are correlated. In particular, if the correlation is negative (i.e. probability decreases as impact increases), a random ranking is actually better than that provided by the risk matrix. In this situation the information provided by risk matrices is “worse than useless” (a random choice is better!). Negative correlations between probability and impact are actually quite common – many situations involve a mix of high probability-low impact and low probability-high impact risks. See the paper for more on this.
Weak consistency and its implications
With the issues of poor resolution and ranking errors established, Cox asks the question: What can be salvaged? The underlying problem is that the joint distribution of probability and impact is unknown. The standard approach to improving the utility of risk matrices is to attempt to characterise this distribution. This can be done using artificial intelligence tools – and Cox provides references to papers that use some of these techniques to characterise distributions. These techniques typically need plentiful data as they attempt to infer characteristics of the joint distribution from data points. Cox, instead, proposes an approach that is based on general properties of risk matrices – i.e. an approach that prescribes a set of rules that ensure consistency. This has the advantage of being general, and not depending on the availability of data points to characterise the probability distribution.
So what might a consistency criterion look like? Cox suggests that, at the very least, a risk matrix should be able to distinguish reliably between very high and very low risks. He formalises this requirement in his definition of weak consistency, which I quote from the paper:
A risk matrix with more than one “colour” (level of risk priority) for its cells satisfies weak consistency with a quantitative risk interpretation if points in its top risk category (red) represent higher quantitative risks than points in its bottom category (green)
The notion of weak consistency formalises the intuitive expectation that a risk matrix must, at the very least, distinguish between the lowest and highest (quantitative) risks. If it can’t, it is indeed “worse than useless”. Note that weak consistency doesn’t say anything about distinguishing between medium and lowest/highest risks – merely between the lowest and highest.
Having defined weak consistency, Cox derives some of its surprising consequences, which I describe next.
Cox’s First Lemma: If a risk matrix satisfies weak consistency, then no red cell (highest risk category) can share an edge with a green cell (lowest risk category).
Proof: To see how this is plausible, consider the different ways in which a red cell can adjoin a green one. Basically there are only two ways in which this can happen, which I’ve illustrated in Figure 3. Now assume that the quantitative risk of the midpoint of the common edge is a number n (n between 0 and 1). Then if x and y and are the impact and probability, we have
xy=n or y=n/x
So, the locus of all points having the same risk (often called the iso-risk contour) as the midpoint is a rectangular hyperbola with negative slope (i.e. y decreases as x increases). The negative slope (see Figure 3) implies that the points above the iso-risk contour in the green cell have a higher quantitative risk than points below the contour in the red cell. This contradicts weak consistency. Hence – by reductio ad absurdum – it isn’t possible to have a green cell and a red cell with a common edge.

Figure 3: Figure for Lemma 1
Cox’s Second Lemma: if a risk matrix satisfies weak consistency and has at least two colours (green in lower left and red in upper right, if axes are oriented to depict increasing probability and impact), then no red cell can occur in the bottom row or left column of the matrix.
Proof: Assume it is possible to have a red cell in the bottom row or left column. Now consider an iso-risk contour for a sufficiently small risk (i.e. a contour that passes through the lower left-most green cell). By the properties of rectangular hyperbolas, this contour must pass through all cells in the bottom row and the left-most column, as shown in Figure 4. Thus, by an argument similar to the one of the previous lemma, all points below the iso-risk contour in either of the red cells have a smaller quantitative risk than point above it in the green cell. This violates weak consistency, and hence the assumption is incorrect.

Figure 4: Figure for Lemma 2
An implication that follows directly from the above lemmas is that any risk matrix that satisfies weak consistency must have at least three colours!
Surprised? I certainly was when I first read this.
Between-ness and its implications
If a risk matrix provides a qualitative representation of the actual qualitative risks, then small changes in the probability or impact should not cause discontinuous jumps in risk categorisation from lowest to highest category without going through the intermediate category. (Recall, from the previous section, that a weakly consistent matrix must have at least three colours).
This expectation is formalised in the axiom of between-ness:
A risk matrix satisfies the axiom of between-ness if every positively sloped line segment that lies in a green cell at its lower end and a red cell at its upper end must pass through at least one intermediate cell (i.e. one that is neither red nor green).
By definition, no 2×2 cell can satisfy between-ness. Further, amongst 3×3 matrices, only one colour scheme satisfies both weak consistency and between-ness. This is the matrix shown in Figure 1: green in the left and bottom columns , red in upper right-most cell and yellow in all other cells. This, to me, is a truly amazing consequence of a couple of simple, intuitive axioms.
Consistent colouring and its implications
The basic idea behind consistent colouring is that risks that have the identical quantitative values should have the same qualitative ratings. This is impossible to achieve in a discrete risk matrix because iso-risk contours cannot coincide with cell boundaries (Why? Because iso-risk contours have negative slopes whereas cell boundaries have zero or infinite slope – i.e. they are horizontal or vertical lines). So, Cox suggests the following: enforce consistent colouring for extreme categories only – red and green – allowing violations for intermediate categories. What this means is that cells that contain iso-risk contours which pass through other red cells (“red contours”) must be red and cells that contain iso-risk contours which pass through other green cells (“green contours”) must be green. Hence the following definition of consistent colouring:
- A cell is red if it contains points with quantitative risks at least as high as those in other red cells, and does not contain points with quantitative risks as small as those on any green cell.
- A cell is green if it contains points with risks at least as small as those in other green cells, and does not contain points with quantitative risks as high as those in any red cell.
- A cell has an intermediate colour only if it a) lies between a red cell and a green cell or b) it contains points with quantitative risks higher than those in some red cells and also points with quantitative risks lower than those in some green cells.
An iso-risk contour is green if it passes through one or more green cells but no red cells and a red contour is one which passes through one or more red cells but no green cells. Consistent colouring then implies that cells with red contours and no green contours are red; and cells with green contours and no red contours are green (and, obviously, cells with contours of both colours are intermediate)
Implications of the three axioms – Cox’s Risk Matrix Theorem
So, after a longish journey, we have three axioms: weak consistency, between-ness and consistent colouring. With that done, Cox rolls out his theorem – which I dub Cox’s Risk Matrix Theorem (not to be confused with Cox’s Theorem from statistics!), which can be stated as follows:
In a risk matrix satisfying weak consistency, between-ness and consistent colouring:
a) All cells in the leftmost column and in the bottom row are green.
b) All cells in the second column from the left and the second row from the bottom are non-red.
The proof is a bit long, so I’ll omit it, making a couple of plausibility arguments instead:
- The lower leftmost cell is green (by definition), and consistent colouring implies that all contours that lie below the one passing through the upper right corner of this cell must also be green because a) they pass through the lower leftmost cell which is green and b) none of the other cells they pass through are red (by Cox’s second lemma). The other cells on the lowest or leftmost edge of the matrix can only be intermediate or green. That they cannot be intermediate is a consequence of between-ness.
- That the second row and second column must be non-red is also easy to see: assume any of these cells to be red. We then have a red cell adjoining a green cell, which violates between-ness.
I’ll leave it at that, referring the interested reader to the paper for a complete proof.
Cox’s theorem has an immediate corollary which is particularly interesting for project managers who use 3×3 and 4×4 risk matrices:
A tricoloured 3×3 or 4×4 matrix that satisfies weak consistency, between-ness and consistent colouring can have only the following (single!) colour scheme:
a) Leftmost column and bottom row coloured green.
b) Top right cell (for 3×3) or four top right cells (for 4×4) coloured red.
c) All other cells coloured yellow.
Proof: Cox’s theorem implies that the leftmost column and bottom row are green. The top right cell must be red (since it is a tricoloured matrix). Consistent colouring implies that the two cells adjoining this cell (in a 4×4 matrix) and the one diagonally adjacent must also be red (this cannot be so for a 3×3 matrix because these cells would adjoin a green cell which violates Cox’s first lemma). All other cells must be yellow by between-ness.
This result is quite amazing. From three very intuitive axioms Cox derives essentially the only possible colouring scheme for 3×3 and 4×4 risk matrices.
Conclusion
This brings me to the end of this post on the Cox’s axiomatic approach to building logically consistent risk matrices. I highly recommend reading the original paper for more. Although it presents some fairly involved arguments, it is very well written. The arguments are presented with clarity and logical surefootedness, and the assumptions underlying each argument are clearly laid out. The three principles (or axioms) proposed are intuitively appealing – even obvious – but their consequences are quite unexpected (witness the unique colouring scheme for 3×3 and 4×4 matrices). Further, the arguments leading up to the lemmas and theorems bring up points that are worth bearing in mind when using risk matrices in practical situations.
In closing I should mention that the paper also discusses some other limitations of risk matrices that flow from these principles: in particular, spurious risk resolution and inappropriate resource allocation based on qualitative risk categorisation. For reasons of space, and the very high likelihood that I’ve already tested my readers’ patience to near (if not beyond) breaking point, I’ll defer a discussion of these to a future post.
Note added on 20 December, 2009:
See this post for a visual representation of the above discussion of Cox’s risk matrix theorem and the comments that follow.


