Archive for the ‘Risk analysis’ Category
The danger within: internally-generated risks in projects
Introduction
In their book, Waltzing with Bears, Tom DeMarco and Timothy Lister coined the phrase, “risk management is project management for adults”. Twenty years on, it appears that their words have been taken seriously: risk management now occupies a prominent place in BOKs, and has also become a key element of project management practice.
On the other hand, if the evidence is to be believed (as per the oft quoted Chaos Report, for example), IT projects continue to fail at an alarming rate. This is curious because one would have expected that a greater focus on risk management ought to have resulted in better outcomes. So, is it possible at all that risk management (as it is currently preached and practiced in IT project management) cannot address certain risks…or, worse, that there are certain risks are simply not recognized as risks?
Some time ago, I came across a paper by Richard Barber that sheds some light on this very issue. This post elaborates on the nature and importance of such “hidden” risks by drawing on Barber’s work as well as my experiences and those of my colleagues with whom I have discussed the paper.
What are internally generated risks?
The standard approach to risk is based on the occurrence of events. Specifically, risk management is concerned with identifying potential adverse events and taking steps to reduce either their probability of occurrence or their impact. However, as Barber points out, this is a limited view of risk because it overlooks adverse conditions that are built into the project environment. A good example of this is an organizational norm that centralizes decision making at the corporate or managerial level. Such a norm would discourage a project manager from taking appropriate action when confronted with an event that demands an on-the-spot decision. Clearly, it is wrong-headed to attribute the risk to the event because the risk actually has its origins in the norm. In other words, it is an internally generated risk.
(Note: the notion of an internally generated risk is akin to the risk as a pathogen concept that I discussed in this post many years ago.)
Barber defines an internally generated risk as one that has its origin within the project organisation or its host, and arises from [preexisting] rules, policies, processes, structures, actions, decisions, behaviours or cultures. Some other examples of such risks include:
- An overly bureaucratic PMO.
- An organizational culture that discourages collaboration between teams.
- An organizational structure that has multiple reporting lines – this is what I like to call a pseudo-matrix organization 🙂
These factors are similar to those that I described in my post on the systemic causes of project failure. Indeed, I am tempted to call these systemic risks because they are related to the entire system (project + organization). However, that term has already been appropriated by the financial risk community.
Since the term is relatively new, it is important to draw distinctions between internally generated and other types of risks. It is easy to do so because the latter (by definition) have their origins outside the hosting organization. A good example of the latter is the risk of a vendor not delivering a module on time or worse, going into receivership prior to delivering the code.
Finally, there are certain risks that are neither internally generated nor external. For example, using a new technology is inherently risky simply because it is new. Such a risk is inherent rather than internally generated or external.
Understanding the danger within
The author of the paper surveyed nine large projects with the intent of getting some insight into the nature of internally generated risks. The questions he attempted to address are the following:
- How common are these risks?
- How significant are they?
- How well are they managed?
- What is the relationship between the ability of an organization to manage such risks and the organisation’s project management maturity level (i.e. the maturity of its project management processes)
Data was gathered through group workshops and one-on-one interviews in which the author asked a number of questions that were aimed at gaining insight into:
- The key difficulties that project managers encountered on the projects.
- What they perceived to be the main barriers to project success.
The aim of the one-on-one interviews was to allow for a more private setting in which sensitive issues (politics, dysfunctional PMOs and brain-dead rules / norms) could be freely discussed.
The data gathered was studied in detail, with the intent of identifying internally generated risks. The author describes the techniques he used to minimize subjectivity and to ensure that only significant risks were considered. I will omit these details here, and instead focus on his findings as they relate to the questions listed above.
Commonality of internally generated risks
Since organizational rules and norms are often flawed, one might expect that internally generated risks would be fairly common in projects. The author found that this was indeed the case with the projects he surveyed: in his words, the smallest number of non-trivial internally generated risks identified in any of the nine projects was 15, and the highest was 30! Note: the identification of non-trivial risks was done by eliminating those risks that a wide range of stakeholders agreed as being unimportant.
Unfortunately, he does not explicitly list the most common internally-generated risks that he found. However, there are a few that he names later in the article. These are:
- Resource allocation (see my article on the resource allocation syndrome for much more on this)
- Inadequate sponsorship (see my post on the systemic roots of project failure for more on this)
I suspect that experienced project managers would be able to name many more.
Significance of internally generated risks
Determining the significance of these risks is tricky because one has to figure out their probability of occurrence. The impact is much easier to get a handle on, as one has a pretty good idea of the consequences of such risks should they eventuate. (Question: What happens if there is inadequate sponsorship? Answer: the project is highly likely to fail!). The author attempted to get a qualitative handle on the probability of occurrence by asking relevant stakeholders to estimate the likelihood of occurrence. Based on the responses received, he found that a large fraction of the internally-generated risks are significant (high probability of occurrence and high impact).
Management of internally generated risks
To identify whether internally generated risks are well managed, the author asked relevant project teams to look at all the significant internal risks on their project and classify them as to whether or not they had been identified by the project team prior to the research. He found that in over half the cases, less than 50% of the risks had been identified. However, most of the risks that were identified were not managed!
The relationship between project management maturity and susceptibility to internally generated risk
Project management maturity refers to the level of adoption of standard good practices within an organization. Conventional wisdom tells us that there should be an inverse correlation between maturity levels and susceptibility to internally generated risk – the higher the maturity level, the lower the susceptibility.
The author assessed maturity levels by interviewing various stakeholders within the organization and also by comparing the processes used within the organization to well-known standards. The results indicated a weak negative correlation – that is, organisations with a higher level of maturity tended to have a smaller number of internally generated risks. However, as the author admits, one cannot read much into this finding as the correlation was weak.
Discussion
The study suggests that internally generated risks are common and significant on projects. However, the small sample size also suggests that more comprehensive surveys are needed. Nevertheless, anecdotal evidence from colleagues who I spoke with suggests that the findings are reasonably robust. Moreover, it is also clear (both, from the study and my conversations) that these risks are not very well managed. There is a good reason for this: internally generated risks originate in human behavior and / or dysfunctional structures. These tend to be a difficult topic to address in an organizational setting because people are unlikely to tell those above them in the hierarchy that they (the higher ups) are the cause of a problem. A classic example of such a risk is estimation by decree – where a project team is told to just get it done by a certain date. Although most project managers are aware of such risks, they are reluctant to name them for obvious reasons.
Conclusion
I suspect most project managers who work in corporate environments will have had to grapple with internally generated risks in one form or another. Although traditional risk management does not recognize these risks as risks, seasoned project managers know from experience that people, politics or even processes can pose major problems to smooth working of projects. However, even when recognised for what they are, these risks can be hard to tackle because they lie outside a project manager’s sphere of influence. They therefore tend to become those proverbial pachyderms in the room – known to all but never discussed, let alone documented….and therein lies the danger within.
The illusion of enterprise risk management – a paper review
Introduction
Enterprise risk management (ERM) refers to the process by which uncertainties are identified, analysed and managed from an organization-wide perspective. In principle such a perspective enables organisations to deal with risks in a holistic manner, avoiding the silo mentality that plagues much of risk management practice. This is the claim made of ERM at any rate, and most practitioners accept it as such. However, whether the claim really holds is another matter altogether. Unfortunately, most of the available critiques of ERM are written for academics or risk management experts. In this post I summarise a critique of ERM presented in a paper by Michael Power entitled, The Risk Management of Nothing.
I’ll begin with a brief overview of ERM frameworks and then summarise the main points of the paper along with some of my comments and annotations.
ERM Frameworks and Definitions
What is ERM?
The best way to answer this question is to look at a couple of well-known ERM frameworks, one from the Casualty Actuarial Society (CAS) and the other from the Committee of Sponsoring Organisations of the Treadway Commission (COSO).
CAS defines ERM as:
… the discipline by which an organization in any industry assesses, controls, exploits, finances, and monitors risks from all sources for the purpose of increasing the organization’s short- and long-term value to its stakeholders.
See this article for an overview of ERM from actuarial perspective.
COSO defines ERM as:
…a process, effected by an entity’s board of directors, management and other personnel, applied in strategy setting and across the enterprise, designed to identify potential events that may affect the entity, and manage risk to be within its risk appetite, to provide reasonable assurance regarding the achievement of entity objectives.
The term risk appetite in the above definition refers to the risk an organisation is willing to bear. See the first article in the June 2003 issue of Internal Auditor for more on the COSO perspective on ERM.
In both frameworks, the focus is very much on quantifying risks through (primarily) financial measures and on establishing accountability for managing these risks in a systematic way.
All this sounds very sensible and uncontroversial. So, where’s the problem?
The problems with ERM
The author of the paper begins with the observation that the basic aim of ERM is to identify risks that can affect an organisation’s objectives and then design controls and mitigation strategies that reduce these risks (collectively) to below a predetermined value that is specified by the organisation’s risk appetite. Operationally, identified risks are monitored and corrective action is taken when they go beyond limits specified by the controls, much like the operation of a thermostat.
In this view, risk management is a mechanistic process. Failures of risk management are seen more as being due to “not doing it right” (implementation failure) or politics getting in the way (organizational friction), rather than a problem with the framework itself. The basic design of the framework is rarely questioned.
Contrary to common wisdom, the author of the paper believes that the design of ERM is flawed in the following three ways:
- The idea of a single, organisation-wide risk appetite is simplistic.
- The assumption that risk can be dealt with by detailed, process-based rules (suitable for audit and control) is questionable.
- The undue focus on developing financial metrics and controls blind it to “bigger picture”, interconnected risks because these cannot be quantified or controlled by such mechanisms.
We’ll now take a look at each of the above in some detail
Appetite vs. appetisation
As mentioned earlier, risk appetite is defined as the risk the organisation is willing to bear. Although ERM frameworks allow for qualitative measures of risk appetite, most organisations implementing ERM tend to prefer quantitative ones. This is a problem because the definition of risk appetite can vary significantly across an organization. For example, the sales and audit functions within an organisation could (will!) have different appetites for risk. As another example, familiar to anyone who reads the news, is that there is usually a big significant gap between the risk appetites of financial institutions and regulatory authorities.
The difference in risk appetites of different stakeholder groups is a manifestation of the fact that risk is a social construct – different stakeholder groups view a given risk in different ways, and some may not even see certain risks as risks (witness the behaviour of certain financial “masters of the universe”)
Since a single, organisation-wide risk appetite is difficult to come up with, the author suggests a different approach – one which takes into account the multiplicity of viewpoints in an organisation; a process he calls “risk appetizing”. This involves getting diverse stakeholders to achieve a consensus / agreement on what constitutes risk appetite. Power argues that this process of reconciling different viewpoints of risk would lead to a more realistic view of the risk the organization is willing to bear. Quoting from the paper:
Conceptualising risk appetising as a process might better direct risk management attention to where it has likely been lacking, namely to the multiplicity of interactions which shape operational and ethical boundaries at the level of organizational practice. COSO-style ERM principles effectively limit the concept of risk appetite within a capital measurement discourse. Framing risk appetite as the process through which ethics and incentives are formed and reformed would not exclude this technical conception, but would bring it closer to the insights of several decades of organization theory.
Explicitly acknowledging the diversity of viewpoints on risk is likely to be closer to reality because:
…a conflictual and pluralistic model is more descriptive of how organizations actually work, and makes lower demands on organizational and political rationality to produce a single ‘appetite’ by explicitly recognising and institutionalising processes by which different appetites and values can be mediated.
Such a process is difficult because it involves getting people who have different viewpoints to agree on what constitutes a sensible definition of risk appetite.
A process bias
A bigger problem, in Power’s view, is that the ERM frameworks overemphasise financial / accounting measures and processes as a means of quantifying and controlling risk. As he puts it ERM:
… is fundamentally an accounting-driven blueprint which emphasises a controls-based approach to risk management. This design emphasis means that efforts at implementation will have an inherent tendency to elaborate detailed controls with corresponding documents trails.
This is a problem because it leads to a “rule-based compliance” mentality wherein risks are managed in a mechanical manner, using bureaucratic processes as a substitute for real thought about risks and how they should be managed. Such a process may work in a make-believe world where all risks are known, but is unlikely to work in one in which there is a great deal of ambiguity.
Power makes the important point that rule-based compliance chews up organizational resources. The tangible effort expended on compliance serves to reassure organizations that they are doing something to manage risks. This is dangerous because it lulls them into a false sense of security:
Rule-based compliance lays down regulations to be met, and requires extensive evidence, audit trails and box ‘checking’. All this demands considerable work and there is daily pressure on operational staff to process regulatory requirements. Yet, despite the workload volume pressure, this is also a cognitively comfortable world which focuses inwards on routine systems and controls. The auditability of this controls architecture can be theorized as a defence against anxiety and enables organizational agents to feel that their work conforms to legitimised principles.
In this comfortable, prescriptive world of process-based risk management, there is little time to imagine and explore what (else) could go wrong. Further, the latter is often avoided because it is a difficult and often uncomfortable process:
…the imagination of alternative futures is likely to involve the production of discomfort, as compared with formal ‘comfort’ of auditing. The approach can take the form of scenario analysis in which participants from different disciplines in an organization can collectively track the trajectory of potential decisions and events. The process begins as an ‘encounter’ with risk and leads to the confrontation of limitation and ambiguity.
Such a process necessarily involves debate and dialogue – it is essentially a deliberative process. And as Power puts it:
The challenge is to expand processes which support interaction and dialogue and de-emphasise due process – both within risk management practice and between regulator and regulated.
This is right of course, but that’s not all: a lot of other process-focused disciplines such as project management would also benefit by acknowledging and responding to this challenge.
A limited view of embeddedness
One of the imperatives of ERM is to “embed” risk management within organisations. Among other things, this entails incorporating risk management explicitly into job descriptions, and making senior managers responsible for managing risks. Although this is a step in the right direction, Power argues that the concept of embeddeness as articulated in ERM remains limited because it focuses on specific business entities, ignoring the wider environment and context in which they exist. The essential (but not always obvious) connections between entities are not necessarily accounted for. As Power puts it:
ERM systems cannot represent embeddedness in the sense of interconnectedness; its proponents seem only to demand an intensification of embedding at the individual entity level. Yet, this latter kind of embedding of a compliance driven risk management, epitomised by the Sarbanes-Oxley legislation, is arguably a disaster in itself, by tying up resources and, much worse, cognition and attention in ‘auditized’ representations of business processes.
In short: the focus on following a process-oriented approach to risk management – as mandated by frameworks – has the potential to de-focus attention from risks that are less obvious, but are potentially more significant.
Addressing the limitations
Power believes the flaws in ERM can be addressed by looking to the practice of business continuity management (BCM). BCM addresses the issue of disaster management – i.e. how to keep an organisation functioning in the event of a disaster. Consequently, there is a significant overlap between the aims of BCM and ERM. However, unlike ERM, BCM draws specialists from different fields and emphasizes collective action. Such an approach is therefore more likely to take a holistic view of risk, and that is the real point.
Regardless of the approach one takes, the point is to involve diverse stakeholders and work towards a shared (enterprise-wide) understanding of risks. Only then will it be possible to develop a risk management plan that incorporates the varying, even contradictory, perspectives that exist within an organisation. There are many techniques to work towards a shared understanding of risks, or any other issues for that matter. Some of these are discussed at length in my book.
Conclusion
Power suggests that ERM, as articulated by bodies such as CAS and COSO, flawed because:
- It attempts to quantify risk appetite at the organizational level – an essentially impossible task because different organizational stakeholders will have different views of risk. Risk is a social construct.
- It advocates a controls and rule-based approach to managing risks. Such a prescriptive “best” practice approach discourages debate and dialogue about risks. Consequently, many viewpoints are missed and quite possibly, so are many risks.
- Despite the rhetoric of ERM, implemented risk management controls and processes often overlook connections and dependencies between entities within organisations. So, although risk management appears to be embedded within the organisation, in reality it may not be so.
Power suggests that ERM practice could learn a few lessons from Business Continuity Management (BCM), in particular about the interconnected nature of business risks and the collective action needed to tackle them. Indeed, any approach that attempts to reconcile diverse risk viewpoints will be a huge improvement on current practice. Until then ERM will continue to be an illusion, offering false comfort to those who are responsible for managing risk.
The shape of things to come: an essay on probability in project estimation
Introduction
Project estimates are generally based on assumptions about future events and their outcomes. As the future is uncertain, the concept of probability is sometimes invoked in the estimation process. There’s enough been written about how probabilities can be used in developing estimates; indeed there are a good number of articles on this blog – see this post or this one, for example. However, most of these writings focus on the practical applications of probability rather than on the concept itself – what it means and how it should be interpreted. In this article I address the latter point in a way that will (hopefully!) be of interest to those working in project management and related areas.
Uncertainty is a shape, not a number
Since the future can unfold in a number of different ways one can describe it only in terms of a range of possible outcomes. A good way to explore the implications of this statement is through a simple estimation-related example:
Assume you’ve been asked to do a particular task relating to your area of expertise. From experience you know that this task usually takes 4 days to complete. If things go right, however, it could take as little as 2 days. On the other hand, if things go wrong it could take as long as 8 days. Therefore, your range of possible finish times (outcomes) is anywhere between 2 to 8 days.
Clearly, each of these outcomes is not equally likely. The most likely outcome is that you will finish the task in 4 days. Moreover, the likelihood of finishing in less than 2 days or more than 8 days is zero. If we plot the likelihood of completion against completion time, it would look something like Figure 1.

Figure 1: Likelihood of finishing on day 2, day 4 and day 8.
Figure 1 begs a couple of questions:
- What are the relative likelihoods of completion for all intermediate times – i.e. those between 2 to 4 days and 4 to 8 days?
- How can one quantify the likelihood of intermediate times? In other words, how can one get a numerical value of the likelihood for all times between 2 to 8 days? Note that we know from the earlier discussion that this must be zero for any time less than 2 or greater than 8 days.
The two questions are actually related: as we shall soon see, once we know the relative likelihood of completion at all times (compared to the maximum), we can work out its numerical value.
Since we don’t know anything about intermediate times (I’m assuming there is no historical data available, and I’ll have more to say about this later…), the simplest thing to do is to assume that the likelihood increases linearly (as a straight line) from 2 to 4 days and decreases in the same way from 4 to 8 days as shown in Figure 2. This gives us the well-known triangular distribution.
Note: The term distribution is simply a fancy word for a plot of likelihood vs. time.

Figure 2: Triangular distribution fitted to points in Figure 1
Of course, this isn’t the only possibility; there are an infinite number of others. Figure 3 is another (admittedly weird) example.

FIgure 3: Another distribution that fits the points in Figure 1
Further, it is quite possible that the upper limit (8 days) is not a hard one. It may be that in exceptional cases the task could take much longer (say, if you call in sick for two weeks) or even not be completed at all (say, if you leave for that mythical greener pasture). Catering for the latter possibility, the shape of the likelihood might resemble Figure 4.

Figure 4: A distribution that allows for a very long (potentially) infinite completion time
From the figures above, we see that uncertainties are shapes rather than single numbers, a notion popularised by Sam Savage in his book, The Flaw of Averages. Moreover, the “shape of things to come” depends on a host of factors, some of which may not even be on the radar when a future event is being estimated.
Making likelihood precise
Thus far, I have used the word “likelihood” without bothering to define it. It’s time to make the notion more precise. I’ll begin by asking the question: what common sense properties do we expect a quantitative measure of likelihood to have?
Consider the following:
- If an event is impossible, its likelihood should be zero.
- The sum of likelihoods of all possible events should equal complete certainty. That is, it should be a constant. As this constant can be anything, let us define it to be 1.
In terms of the example above, if we denote time by 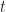
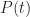
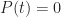
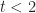
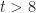
And
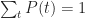
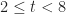
Where 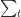
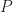

With these assumptions in hand, we can now obtain numerical values for the probability of completion for all times between 2 and 8 days. This can be figured out by noting that the area under the probability curve (the triangle in figure 2 and the weird shape in figure 3) must equal 1. I won’t go into any further details here, but those interested in the maths for the triangular case may want to take a look at this post where the details have been worked out.
The meaning of it all
(Note: parts of this section borrow from my post on the interpretation of probability in project management)
So now we understand how uncertainty is actually a shape corresponding to a range of possible outcomes, each with their own probability of occurrence. Moreover, we also know, in principle, how the probability can be calculated for any valid value of time (between 2 and 8 days). Nevertheless, we are still left with the question as to what a numerical probability really means.
As a concrete case from the example above, what do we mean when we say that there is 100% chance (probability=1) of finishing within 8 days? Some possible interpretations of such a statement include:
- If the task is done many times over, it will always finish within 8 days. This is called the frequency interpretation of probability, and is the one most commonly described in maths and physics textbooks.
- It is believed that the task will definitely finish within 8 days. This is called the belief interpretation. Note that this interpretation hinges on subjective personal beliefs.
- Based on a comparison to similar tasks, the task will finish within 8 days. This is called the support interpretation.
Note that these interpretations are based on a paper by Glen Shafer. Other papers and textbooks frame these differently.
The first thing to note is how different these interpretations are from each other. For example, the first one offers a seemingly objective interpretation whereas the second one is unabashedly subjective.
So, which is the best – or most correct – one?
A person trained in science or mathematics might claim that the frequency interpretation wins hands down because it lays out an objective, well -defined procedure for calculating probability: simply perform the same task many times and note the completion times.
Problem is, in real life situations it is impossible to carry out exactly the same task over and over again. Sure, it may be possible to do almost the same task, but even straightforward tasks such as vacuuming a room or baking a cake can hold hidden surprise (vacuum cleaners do malfunction and a friend may call when one is mixing the batter for a cake). Moreover, tasks that are complex (as is often the case in the project work) tend to be unique and can never be performed in exactly the same way twice. Consequently, the frequency interpretation is great in theory but not much use in practice.
“That’s OK,” another estimator might say,” when drawing up an estimate, I compared it to other similar tasks that I have done before.”
This is essentially the support interpretation (interpretation 3 above). However, although this seems reasonable, there is a problem: tasks that are superficially similar will differ in the details, and these small differences may turn out to be significant when one is actually carrying out the task. One never knows beforehand which variables are important. For example, my ability to finish a particular task within a stated time depends not only on my skill but also on things such as my workload, stress levels and even my state of mind. There are many external factors that one might not even recognize as being significant. This is a manifestation of the reference class problem.
So where does that leave us? Is probability just a matter of subjective belief?
No, not quite: in reality, estimators will use some or all of three interpretations to arrive at “best guess” probabilities. For example, when estimating a project task, a person will likely use one or more of the following pieces of information:
- Experience with similar tasks.
- Subjective belief regarding task complexity and potential problems. Also, their “gut feeling” of how long they think it ought to take. These factors often drive excess time or padding that people work into their estimates.
- Any relevant historical data (if available)
Clearly, depending on the situation at hand, estimators may be forced to rely on one piece of information more than others. However, when called upon to defend their estimates, estimators may use other arguments to justify their conclusions depending on who they are talking to. For example, in discussions involving managers, they may use hard data presented in a way that supports their estimates, whereas when talking to their peers they may emphasise their gut feeling based on differences between the task at hand and similar ones they have done in the past. Such contradictory representations tend to obscure the means by which the estimates were actually made.
Summing up
Estimates are invariably made in the face of uncertainty. One way to get a handle on this is by estimating the probabilities associated with possible outcomes. Probabilities can be reckoned in a number of different ways. Clearly, when using them in estimation, it is crucial to understand how probabilities have been derived and the assumptions underlying these. We have seen three ways in which probabilities are interpreted corresponding to three different ways in which they are arrived at. In reality, estimators may use a mix of the three approaches so it isn’t always clear how the numerical value should be interpreted. Nevertheless, an awareness of what probability is and its different interpretations may help managers ask the right questions to better understand the estimates made by their teams.


