Archive for the ‘Statistics’ Category
Monte Carlo simulation of multiple project tasks – three examples and some general comments
Introduction
In my previous post I demonstrated the use of a Monte Carlo technique in simulating a single project task with completion times described by a triangular distribution. My aim in that article was to: a) describe a Monte Carlo simulation procedure in enough detail for someone interested to be able to reproduce the calculations and b) show that it gives sensible results in a situation where the answer is known. Now it’s time to take things further. In this post, I present simulations for two tasks chained together in various ways. We shall see that, even with this small increase in complexity (from one task to two), the results obtained can be surprising. Specifically, small changes in inter-task dependencies can have a huge effect on the overall (two-task) completion time distribution. Although, this is something that that most project managers have experienced in real life, it is rarely taken in to account by traditional scheduling techniques. As we shall see, Monte Carlo techniques predict such effects as a matter of course.
Background
The three simulations discussed here are built on the example that I used in my previous article, so it’s worth spending a few lines for a brief recap of that example. The task simulated in the example was assumed to be described by a triangular distribution with minimum completion time (


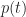

Figure 1 - PDF for triangular distribution (tmin=2, tml=4, tmax=8)
Figure 2 depicts the associated cumulative distribution function (CDF), 

Figure 2 - PDF for triangular distribution (tmin=2, tml=4, tmax=6)
The equations describing the PDF and CDF are listed in equations 4-7 of my previous article. I won’t rehash them here as they don’t add anything new to the discussion – please see the article for all the gory algebraic details and formulas. Now, with that background, we’re ready to move on to the examples.
Two tasks in series with no inter-task delay
As a first example, let’s look at two tasks that have to be performed sequentially – i.e. the second task starts as soon as the first one is completed. To simplify things, we’ll also assume that they have identical (triangular) distributions as described earlier and shown in Figure 1 (excepting , of course, that the distribution is shifted to the right for the second task – since it starts after the first one finishes). We’ll also assume that the second task begins right after the first one is completed (no inter-task delay) – yes, this is unrealistic, but bear with me. The simulation algorithm for the combined tasks is very similar to the one for a single task (described in detail in my previous post). Here’s the procedure:
- For each of the two tasks, generate a set of N random numbers. Each random number generated corresponds to the cumulative probability of completion for a single task on that particular run.
- For each random number generated, find the time corresponding to the cumulative probability by solving equation 6 or 7 in my previous post.
- Step 2 gives N sets of completion times. Each set has two completion times – one for each tasks.
- Add up the two numbers in each set to yield the comple. The resulting set corresponds to N simulation runs for the combined task.
I then divided the time interval from t=4 hours (min possible completion time for both tasks) to t=16 hours (max possible completion time for both tasks) into bins of 0.25 hrs each, and then assigned each combined completion time to the appropriate bin. For example, if the predicted completion time for a particular run was 9.806532 hrs, it was assigned to the bin corresponding to 0.975 hrs. The resulting histogram is shown in Figure 3 below (click on image to view the full-size graphic).

Figure 3 - Frequency histogram for tasks in series with no inter-task delay
[An aside: compare the histogram in Figure 3 to the one for a single task (Figure 1): the distribution for the single task is distinctly asymmetric (the peak is not at the centre of the distribution) whereas the two task histogram is nearly symmetric. This surprising result is a consequence of the Central Limit Theorem (CLT) – which states that the sum of many identical distributions tends to resemble the Normal (Bell-shaped) distribution, regardless of the shape of the individual distributions. Note that the CLT holds even though the two task distributions are shifted relative to each other – i.e. the second task begins after the first one is completed.]
The simulation also enables us to compute the cumulative probability of completion for the combined tasks (the CDF). This value of the cumulative probability at a particular bin equals the sum of the number of simulations runs in every bin up to (and including) the bin in question, divided by the total number of simulation runs. In mathematical terms this is:
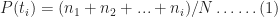
where 
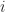


The resulting cumulative probability function is shown in Figure 4. This allows us to answer questions such as: “What is the probability that the tasks will be completed within 10 days?”. Answer: .698, or approximately 70%. (Note: I obtained this number by interpolating between values obtained from equation (1), but this level of precision is uncalled for, particularly because the formula is an approximate one)

Figure 4 - CDF for tasks in series with no inter-task delay
Many project scheduling techniques compute average completion times for component tasks and then add them up to get the expected completion time for the combined task. In the present case the average works out to 9.33 hrs (twice the average for a single task). However, we see from the CDF that there is a significant probability (.43) that we will not finish by this time – and this in a “best-case ” situation where the second task starts immediately after the first one finishes!
[An aside: If one applies the well-known PERT formula 
As interesting as this case is, it is somewhat unrealistic because successor tasks seldom start the instant the predecessor is completed. More often than not, there is a cut-off time before which the successor cannot start – even if there are no explicit dependencies between the two tasks. This observation is a perfect segue into my next example, which is…
Two tasks in series with a fixed earliest start for the successor
Now we’ll introduce a slight complication: let’s assume, as before, that the two tasks are done one after the other but that the earliest the second task can start is at 
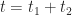

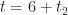
I divided the time interval from t=4hrs to t=20 hrs into bins of 0.25 hr duration (much as I did before) and then assigned each combined completion time to the appropriate bin. The resulting histogram is shown in Figure 5.

Figure 5 - Frequency histogram for tasks in series with inter-task delay
Comparing Figure 5 to Figure 3, we see that the earliest possible finish time now increases from 4 hrs to 8 hrs. This is no surprise, as we built this in to our assumption. Further, as one might expect, the distribution is distinctly asymmetric – with a minimum completion time of 8 hrs, a most likely time between 10 and 11 hrs and a maximum completion time of about 15 hrs.
Figure 6 shows the cumulative probability of completion for this case.

Figure 6 - CDF for tasks in series with inter-task delay
Because of the delay condition, it is impossible to calculate the average completion from the formulas for the triangular distribution – we have to obtain it from the simulation. The average can be calculated from the simulation adding up all completion times and dividing by the total number of simulations,

where 
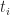
This procedure gave me a value of about 10.8 hrs for the average. From the CDF in Figure 6 one sees that the probability that the combined task will finish by this time is only 0.60 – i.e. there’s only a 60% chance that the task will finish by this time. Any naïve estimation of time would do just as badly unless, of course, one is overly pessimistic and assumes a completion time of 15 – 16 hrs.
From the above it should be evident that the simulation allows one to associate an uncertainty (or probability) with every estimate. If management imposes a time limit of 10 hours, the project manager can refer to the CDF in Figure 6 and figure out the probability of completing the task by that time (there’s a 40 % chance of completion by 10 hrs). Of course, the reliability of the numbers depend on how good the distribution is. But the assumptions that have gone into the model are known – the optimistic, most likely and pessimistic times and the form of the distribution – and these can be refined as one gains experience.
Two tasks in parallel
My final example is the case of two identical tasks performed in parallel. As above, I’ll assume the uncertainty in each task is characterized by a triangular distribution with 
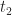
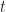

To plot the histogram shown in Figure 7 , I divided the interval from t=2 hrs to t=8 hrs into bins of 0.25 hr duration each (Warning: Note the difference in the time axis scale from Figures 3 and 5!).

Figure 7 - Frequency histogram for tasks in parallel
It is interesting to compare the above histogram with that for an individual task with the same parameters (i.e. the example that was used in my previous post). Figure 8 shows the histograms for the two examples on the same plot (the combined task in red and the single task in blue). As one might expect, the histogram for the combined task is shifted to the right, a consequence of the nonlinear condition on the completion time.

Figure 8 - Histograms for tasks in parallel (red) and single task (blue)
What about the average? I calculated the average as before, by using equation (2) from the previous section. This gives an average of 5.38 hrs (compared to 4.67 hrs for either task, taken individually). Note that the method to calculate the average is the same regardless of the form of the distribution. On the other hand, computing the average from the equations would be a complicated affair, involving a stiff dose of algebra with an optional sprinkling of calculus. Even worse – the calculations would vary from distribution to distribution. There’s no question that simulations are much easier.
The CDF for the overall completion time is also computed easily using equation (1). The resulting plot is shown in Figure 9 (Note the difference in the time axis scale from Figures 4 and 6!). There are no surprises here – excepting how easy it is to calculate once the simulation is done.

Figure 9 - CDF for tasks in parallel
Let’s see what time corresponds to a 90% certainty of completion. A rough estimate for this number can be obtained from Figure 9 – just find the value of t (on the x axis) corresponding to a cumulative probability of 0.9 (on the y axis). This is the graphical equivalent of solving the CDF for time, given the cumulative probability is 0.9. From Figure 9, we get a time of approximately 6.7 hrs. [Note: we could get a more accurate number by fitting the points obtained from equation (1) to a curve and then calculating the time corresponding to 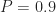
Comparing the two histograms in Figure 8, we expect the biggest differences in cumulative probability to occur at about the t=4 hour mark, because by that time the probability for the individual task has peaked whereas that for the combined task is yet to peak. Let’s see if this is so: from Figure 8, the cumulative probability for t=4 hrs is about .15 and from the CDF for the triangular distribution (equation 6 from my previous post), the cumulative probability at t=4 hours (which is the most likely time) is .333 – double that of the combined task. This, again, isn’t too surprising (once one has Figure 8 on hand). The really nice thing is that we are able to attach uncertainties to all our estimates.
Conclusion
Although the examples discussed above are simple – two identical tasks with uncertainties described by a triangular distribution – they serve to illustrate some of the non-intuitive outcomes when tasks have dependencies. It is also worth noting that although the distribution for the individual tasks is known, the only straightforward way to obtain the distributions for the combined tasks (figures 3, 5 and 7) is through simulations. So, even these simple examples are a good demonstration of the utility of Monte Carlo techniques. Of course, real projects are way more complicated, with diverse tasks distributed in many different ways. To simplify simulations in such cases, one could perform coarse-grained simulations on a small number of high-level tasks, each consisting of a number of low-level, atomic tasks. The high-level tasks could be constructed in such a way as to focus attention on areas of greatest complexity, and hence greatest uncertainty.
As I have mentioned several times in this article and the previous one: simulation results are only as good as the distributions on which they are based. This begs the question: how do we know what’s an appropriate distribution for a given situation? There’s no one-size-fits-all answer to this question. However, for project tasks there are some general considerations that apply. These are:
- There is a minimum time (
- The probability will increase from 0 at
- The probability decreases as time increases beyond
Asymmetric triangular distributions (such as the one used in my examples) are the simplest distributions that satisfy these conditions. Furthermore, a three point estimate is enought to specify a triangular distribution completely – i.e. given a three point estimate there is only one triangular distribution that can be fitted to it. That said, there are several other distributions that can be used; of particular relevance are certain long-tailed distributions.
Finally, I should mention that I make no claims about the efficiency or accuracy of the method presented here: it should be seen as a demonstration rather than a definitive technique. The many commercial Monte Carlo tools available in the market probably offer far more comprehensive, sophisticated and reliable algorithms (Note: I ‘ve never used any of them, so I can’t make any recommendations!). That said, it is always helpful to know the principles behind such tools, if for no other reason than to understand how they work and, more important, how to use them correctly. The material discussed in this and the previous article came out of my efforts to develop an understanding Monte Carlo techniques and how they can be applied to various aspects of project management (they can also be applied to cost estimation, for example). Over the last few weeks I’ve spent many enjoyable evenings developing and running these simulations, and learning from them. I’ll leave it here with the hope that you find my articles helpful in your own explorations of the wonderful world of Monte Carlo simulations.
An introduction to Monte Carlo simulation of project tasks
Introduction
In an essay on the uncertainty of project task estimates, I described how a task estimate corresponds to a probability distribution. Put simply, a task estimate is actually a range of possible completion times, each with a probability of occurrence specified by a distribution. If one knows the distribution, it is possible to answer questions such as: “What is the probability that the task will be completed within x days?”
The reliability of such predictions depends on how faithfully the distribution captures the actual spread of task durations – and therein lie at least a couple of problems. First, the probability distributions for task durations are generally hard to characterise because of the lack of reliable data (estimators are not very good at estimating, and historical data is usually not available). Second, many realistic distributions have complicated mathematical forms which can be hard to characterise and manipulate.
These problems are compounded by the fact that projects consist of several tasks, each one with its own duration estimate and (possibly complicated) distribution. The first issue is usually addressed by fitting distributions to point estimates (such as optimistic, pessimistic and most likely times as in PERT) and then refining these estimates and distributions as one gains experience. The second issue can be tackled by Monte Carlo techniques, which involve simulating the task a number of times (using an appropriate distribution) and then calculating expected completion times based on the results. My aim in this post is to present an example-based introduction to Monte Carlo simulation of project task durations.
Although my aim is to keep things reasonably simple (not too much beyond high-school maths and a basic understanding of probability), I’ll be covering a fair bit of ground. Given this, I’d best to start with a brief description of my approach so that my readers know what coming.
Monte Carlo simulation is an umbrella term that covers a range of approaches that use random sampling to simulate events that are described by known probability distributions. The first task then, is to specify the probability distribution. However, as mentioned earlier, this is generally unknown for task durations. For simplicity, I’ll assume that task duration uncertainty can be described accurately using a triangular probability distribution – a distribution that is particularly easy to handle from the mathematical point of view. The advantage of using the triangular distribution is that simulation results can be validated easily.
Using the triangular distribution isn’t a limitation because the method I describe can be applied to arbitrarily shaped distributions. More important, the technique can be used to simulate what happens when multiple tasks are strung together as in a project schedule (I’ll cover this in a future post). Finally, I’ll demonstrate a Monte Carlo simulation method as applied to a single task described by a triangular distribution. Although a simulation is overkill in this case (because questions regarding durations can be answered exactly without using a simulation), the example serves to illustrate the steps involved in simulating more complex cases – such as those comprising of more than one task and/or involving more complicated distributions.
So, without further ado, let me begin the journey by describing the triangular distribution.
The triangular distribution
Let’s assume that there’s a project task that needs doing, and the person who is going to do it reckons it will take between 2 and 8 hours to complete it, with a most likely completion time of 4 hours. How the estimator comes up with these numbers isn’t important at this stage – maybe there’s some guesswork, maybe some padding or maybe it is really based on experience (as it should be). What’s important is that we have three numbers corresponding to a minimum, most likely and maximum time. To keep the discussion general, we’ll call these
Now, what about the probabilities associated with each of these times?
Since 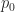

Figure 1: Triangular Distribution
For the simulation, we need to know the equation describing the above distribution. Although Wikipedia will tell us the answer in a mouse-click, it is instructive to figure it out for ourselves. First, note that the area under the triangle must be equal to 1 because the task must finish at some time between
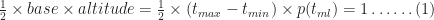
where 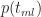
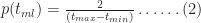
To derive the probability for any time
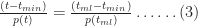
This is a consequence of the fact that the ratios on either side of equation (3) are equal to the slope of the line joining the points 
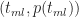

Figure 2
Substituting (2) in (3) and simplifying a bit, we obtain:
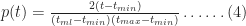
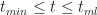
In a similar fashion one can show that the probability for times lying between
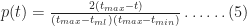

Equations 4 and 5 together describe the probability distribution function (or PDF) for all times between
Another quantity of interest is the cumulative distribution function (or CDF) which is the probability, 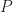

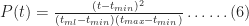
Noting that for 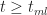
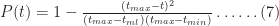
As expected,
To end this section let's plug in the numbers quoted by our estimator at the start of this section: 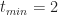
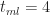
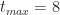


Figure 4 – Triangular CDF (tmin=2, tml=4, tmax=8)
Monte Carlo Simulation of a Single Task
OK, so now we get to the business end of this essay – the simulation. I’ll first outline the simulation procedure and then discuss results for the case of the task described in the previous section (triangular distribution with
So, here’s my simulation procedure:
- Generate a random number between 0 and 1. Treat this number as the cumulative probability,
- Find the time,
- Repeat steps (1) and (2) N times, where N is a “sufficiently large” number – say 10,000.
I did the calculations for 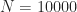
As an example of a simulation run proceeds, here’s the data from my first simulation run: the random number generator returned 0.490474700804856 (call it 0.4905). This is the value of 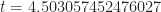

Figure 5
After completing 10,000 simulation runs, I sorted these into bins corresponding to time intervals of .25 hrs, starting from

Figure 6: Distribution of simulation runs
As one might expect, this looks like the triangular distribution shown in Figure 4. There is a difference though: Figure 4 plots probability as a continuous function of time whereas Figure 6 plots the number of simulation runs as a step function of time. To convince ourselves that the two are really the same, lets look at the cumulative probability at 
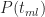
Wrap up
A limitation of the triangular distribution is that it imposes an upper cut-off at
Another point worth mentioning is that simulations can be done at a level higher than that of an indivdual task. In their brilliant book – Waltzing With Bears: Managing Risk on Software Projects – De Marco and Lister demonstrate the use of Monte Carlo methods to simulate various aspects of project – velocity, time, cost etc. – at the project level (as opposed to the task level). I believe it is better to perform simulations at the lowest possible level (although it is a lot more work) – the main reason being that it is easier, and less error-prone, to estimate individual tasks than entire projects. Nevertheless, high level simulations can be very useful if one has reliable data to base these on.
I would be remiss if I didn’t mention some of the various Monte Carlo packages available in the market. I’ve never used any of these, but by all accounts they’re pretty good: see this commercial package or this one, for example. Both products use random number generators and sampling techniques that are far more sophisticated than the simple ones I’ve used in my example.
Finally, I have to admit that the example described in this post is a very complicated way of demonstrating the obvious – I started out with the triangular distribution and then got back the triangular distribution via simulation. My point, however, was to illustrate the method and show that it yields expected results in a situation where the answer is known. In a future post I’ll apply the method to more complex situations- for example, multiple tasks in series and parallel, with some dependency rules thrown in for good measure. Although, I’ll use the triangular distribution for individual tasks, the results will be far from obvious: simulation methods really start to shine as complexity increases. But all that will have to wait for later. For now, I hope my example has helped illustrate how Monte Carlo methods can be used to simulate project tasks.
Note added on 21 Sept 2009:
Follow-up to this article published here.
Note added on 14 Dec 2009:
See this post for a Monte Carlo simulation of correlated project tasks.
Enumeration or analysis? A note on the use and abuse of statistics in project management research
In a detailed and insightful response to my post on bias in project management research, Alex Budzier wrote, “Good quantitative research relies on Theories and has a sound logical explanation before testing something. Bad research gets some data throws it to the wall (aka correlation analysis) and reports whatever sticks.” I believe this is a very important point: a lot of current research in project management uses statistics in an inappropriate manner; using the “throwing data on a wall” approach that Alex refers to in his comment. Often researchers construct models and theories based on data that isn’t sufficiently representative to support their generalisations.
This point is the subject of a paper entitled, On Probability as a Basis for Action, published by Edwards Deming in 1975. In the paper, Deming makes the important distinction between enumerative and analytical studies. The basic difference between the two is that analytical studies are aimed at establishing cause and effect based on data (i.e. building theories that explain why the data is what it is), whereas enumerative studies are concerned with classification (i.e categorising data). In this post I delve into the use (or abuse) of statistics in project management research, with particular reference to enumerative and analytical studies. The discussion presented below is based on Deming’s paper and a very readable note by David and Sarah Kerridge.
Some terminology before diving into the discussion: Deming uses the notion of a frame, which he defines as an aggregate of identifiable physical units of some kind, any or all of which may be selected and investigated. In short: the aggregate of potential samples.
So what’s an enumerative study? In his paper, Deming defines it as one in which, “…action will be taken on the material in the frame studied…The aim of a study in an enumerative problem is descriptive. How many farms or people belong to this or that category? What is the expected out-turn of wheat for this region? How many units in the lot are defective? The aim (in the last example) is not to find out why there are so many or so few units in this or that category: merely how many.”
In contrast, an analytic study is one “in which action will be taken on the process or cause-system that produced the frame studied, the aim being to improve practice in the future…Examples include, comparison of two industrial processes A and B. (Possible) actions: adopt method B over method A, or hold on to A, or continue the experiment (gather more data).“
Deming also provides a criterion by which to distinguish between enumerative and analytic studies. To quote from the paper, “A 100 percent sample of the frame provides the complete answer to the question posed for the enumerative problem, subject to the limitations of the method of investigation. In contrast a 100 percent sample of the frame is inconclusive in an analytic problem“
It may be helpful to illustrate the above via project management examples. A census of tools used by project managers is an enumerative problem: sampling the entire population of project managers provides a complete answer. In contrast, building (or validating) a model of project manager performance is an analytic study: it is not possible, even in principle, to verify the model under all circumstances. To paraphrase Deming: there is no statistical method by which to extrapolate the validity of the model to other project managers or environments. This is the key point. Statistical methods have to be complemented by knowledge of the subject matter – in the case of project manager performance this may include organisational factors, environmental effects, work history and experience of project managers etc. Such knowledge helps the investigator design studies that cover a wide range of circumstances, paving the way for generalisations necessary for theory building. Basically, the sample data must cover the entire range over which generalisations are made. What this means is that the choice of samples depends on the aim of the study. The Kerridges offer some examples in their note, which I reproduce below:
Aim: Discover problems and possibilities, to form a new theory.
Method: Look for interesting groups, where new ideas will be obvious. These
may be focus groups, rather than random samples. Accuracy and rigour aren’t required. But this assumes that the possibilities discovered will be tested by other means, before making any prediction.Aim: Predict the future, to test a general theory.
Method: Study extreme and atypical samples, with great rigour and accuracy.Aim: Predict the future, to help management.
Method: Get samples as close as possible to the foreseeable range of circumstances
in which the prediction will be used in practice.Aim: Change the future, to make it more predictable.
Method: Use statistical process control to remove special causes, and experiment using the PDSA cycle to reduce common cause variation.
Unfortunately, many project management studies that purport to build theories do not exercise appropriate care in study design. The typical offence is that samples used in the studies do not support generalisations made. The resulting theories are thus built on flimsy empirical foundations. To be sure, most offenders label their studies as preliminary (other favoured adjectives include exploratory, tentative initial etc), thereby absolving themselves of responsibility for their irresponsible speculations. That would be OK if such work were followed up by a thorough empirical study, but it often isn’t. I’m loath to point fingers at specific offenders, but readers will find an example or two amongst papers reviewed on this blog. Lest I be accused of making gross and unfair generalisations, I should hasten to add that the reviews also include papers in which statistical analysis is done right (I’ll leave it to the reader to figure out which ones these are…).
To sum up: in this post I’ve discussed the difference between enumerative and analytic studies and its implications for the validity of some published project management research. Enumerative statistics deals with counting and categorisations whereas the analytical studies are concerned with clarifying cause-effect relationships. In analytical work, it is critical that samples are chosen that reflect the stated intent of the work, be it general theory-building or prediction in specific circumstances. Although this distinction should be well understood (having been articulated clearly over quarter a century ago!), it appears that it isn’t always given due consideration in project management research.


