Author Archive
On the accuracy of group estimates
Introduction
The essential idea behind group estimation is that an estimate made by a group is likely to be more accurate than one made by an individual in the group. This notion is the basis for the Delphi method and its variants. In this post, I use arguments involving probabilities to gain some insight into the conditions under which group estimates are more accurate than individual ones.
An insight from conditional probability
Let’s begin with a simple group estimation scenario.
Assume we have two individuals of similar skill who have been asked to provide independent estimates of some quantity, say a project task duration. Further, let us assume that each individual has a probability 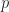
Based on the above, the probability that they both make a correct estimate, 
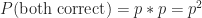
This is a consequence of our assumption that the individual estimates are independent of each other.
Similarly, the probability that they both get it wrong, 

Now we can ask the following question:
What is the probability that both individuals make the correct estimate if we know that they have both made the same estimate?
This can be figured out using Bayes’ Theorem, which in the context of the question can be stated as follows:

In the above equation, 
Similarly, 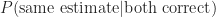
Question: Why?
Answer: If both estimators are correct then they must have made the same estimate (i.e. they must both within be an acceptable range of the right answer).
Finally, 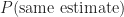
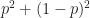
Now lets apply Bayes’ theorem to the following two cases:
- Both individuals are good estimators – i.e. they have a high probability of making a correct estimate. We’ll assume they both have a 90% chance of getting it right (
).
- Both individuals are poor estimators – i.e. they have a low probability of making a correct estimate. We’ll assume they both have a 30% chance of getting it right (
)
Consider the first case. The probability that both estimators get it right given that they make the same estimate is:

Thus we see that the group estimate has a significantly better chance of being right than the individual ones: a probability of 0.9878 as opposed to 0.9.
In the second case, the probability that both get it right is:

The situation is completely reversed: the group estimate has a much smaller chance of being right than an individual estimate!
In summary: estimates provided by a group consisting of individuals of similar ability working independently are more likely to be right (compared to individual estimates) if the group consists of competent estimators and more likely to be wrong (compared to individual estimates) if the group consists of poor estimators.
Assumptions and complications
I have made a number of simplifying assumptions in the above argument. I discuss these below with some commentary.
- The main assumption is that individuals work independently. This assumption is not valid for many situations. For example, project estimates are often made by a group of people working together. Although one can’t work out what will happen in such situations using the arguments of the previous section, it is reasonable to assume that given the right conditions, estimators will use their collective knowledge to work collaboratively. Other things being equal, such collaboration would lead a group of skilled estimators to reinforce each others’ estimates (which are likely to be quite similar) whereas less skilled ones may spend time arguing over their (possibly different and incorrect) guesses. Based on this, it seems reasonable to conjecture that groups consisting of good estimators will tend to make even better estimates than they would individually whereas those consisting of poor estimators have a significant chance of making worse ones.
- Another assumption is that an estimate is either good or bad. In reality there is a range that is neither good nor bad, but may be acceptable.
- Yet another assumption is that an estimator’s ability can be accurately quantified using a single numerical probability. This is fine providing the number actually represents the person’s estimation ability for the situation at hand. However, typically such probabilities are evaluated on the basis of past estimates. The problem is, every situation is unique and history may not be a good guide to the situation at hand. The best way to address this is to involve people with diverse experience in the estimation exercise. This will almost often lead to a significant spread of estimates which may then have to be refined by debate and negotiation.
Real-life estimation situations have a number of other complications. To begin with, the influence that specific individuals have on the estimation process may vary – a manager who is a poor estimator may, by virtue of his position, have a greater influence than others in a group. This will skew the group estimate by a factor that cannot be estimated. Moreover, strategic behaviour may influence estimates in a myriad other ways. Then there is the groupthink factor as well.
…and I’m sure there are many others.
Finally I should mention that group estimates can depend on the details of the estimation process. For example, research suggests that under certain conditions competition can lead to better estimates than cooperation.
Conclusion
In this post I have attempted to make some general inferences regarding the validity of group estimates based on arguments involving conditional probabilities. The arguments suggest that, all other things being equal, a collective estimate from a bunch of skilled estimators will generally be better than their individual estimates whereas an estimate from a group of less skilled estimators will tend to be worse than their individual estimates. Of course, in real life, there are a host of other factors that can come into play: power, politics and biases being just a few. Though these are often hidden, they can influence group estimates in inestimable ways.
Acknowledgement
Thanks go out to George Gkotsis and Craig Brown for their comments which inspired this post.
On the limitations of business intelligence systems
Introduction
One of the main uses of business intelligence (BI) systems is to support decision making in organisations. Indeed, the old term Decision Support Systems is more descriptive of such applications than the term BI systems (although the latter does have more pizzazz). However, as Tim Van Gelder pointed out in an insightful post, most BI tools available in the market do not offer a means to clarify the rationale behind decisions. As he stated, “[what] business intelligence suites (and knowledge management systems) seem to lack is any way to make the thinking behind core decision processes more explicit.”
Van Gelder is absolutely right: BI tools do not support the process of decision-making directly, all they do is present data or information on which a decision can be based. But there is more: BI systems are based on the view that data should be the primary consideration when making decisions. In this post I explore some of the (largely tacit) assumptions that flow from such a data-centric view. My discussion builds on some points made by Terry Winograd and Fernando Flores in their wonderful book, Understanding Computers and Cognition.
As we will see, the assumptions regarding the centrality of data are questionable, particularly when dealing with complex decisions. Moreover, since these assumptions are implicit in all BI systems, they highlight the limitations of using BI systems for making business decisions.
An example
To keep the discussion grounded, I’ll use a scenario to illustrate how assumptions of data-centrism can sneak into decision making. Consider a sales manager who creates sales action plans for representatives based on reports extracted from his organisation’s BI system. In doing this, he makes a number of tacit assumptions. They are:
- The sales action plans should be based on the data provided by the BI system.
- The data available in the system is relevant to the sales action plan.
- The information provided by the system is objectively correct.
- The side-effects of basing decisions (primarily) on data are negligible.
The assumptions and why they are incorrect
Below I state some of the key assumptions of the data-centric paradigm of BI and discuss their limitations using the example of the previous section.
Decisions should be based on data alone: BI systems promote the view that decisions can be made based on data alone. The danger in such a view is that it overlooks social, emotional, intuitive and qualitative factors that can and should influence decisions. For example, a sales representative may have qualitative information regarding sales prospects that cannot be inferred from the data. Such information should be factored into the sales action plan providing the representative can justify it or is willing to stand by it.
The available data is relevant to the decision being made: Another tacit assumption made by users of BI systems is that the information provided is relevant to the decisions they have to make. However, most BI systems are designed to answer specific, predetermined questions. In general these cannot cover all possible questions that managers may ask in the future.
More important is the fact that the data itself may be based on assumptions that are not known to users. For example, our sales manager may be tempted to incorporate market forecasts simply because they are available in the BI system. However, if he chooses to use the forecasts, he will likely not take the trouble to check the assumptions behind the models that generated the forecasts.
The available data is objectively correct: Users of BI systems tend to look upon them as a source of objective truth. One of the reasons for this is that quantitative data tends to be viewed as being more reliable than qualitative data. However, consider the following:
- In many cases it is impossible to establish the veracity of quantitative data, let alone its accuracy. In extreme cases, data can be deliberately distorted or fabricated (over the last few years there have been some high profile cases of this that need no elaboration…).
- The imposition of arbitrary quantitative scales on qualitative data can lead to meaningless numerical measures. See my post on the limitations of scoring methods in risk analysis for a deeper discussion of this point.
- The information that a BI system holds is based the subjective choices (and biases) of its designers.
In short, the data in a BI system does not represent an objective truth. It is based on subjective choices of users and designers, and thus may not be an accurate reflection of the reality it allegedly represents. (Note added on 16 Feb 2013: See my essay on data, information and truth in organisations for more on this point).
Side-effects of data-based decisions are negligible: When basing decisions on data, side-effects are often ignored. Although this point is closely related to the first one, it is worth making separately. For example, judging a sales representative’s performance on sales figures alone may motivate the representative to push sales at the cost of building sustainable relationships with customers. Another example of such behaviour is observed in call centers where employees are measured by number of calls rather than call quality (which is much harder to measure). The former metric incentivizes employees to complete calls rather than resolve issues that are raised in them. See my post entitled, measuring the unmeasurable, for a more detailed discussion of this point.
Although I have used a scenario to highlight problems of the above assumptions, they are independent of the specifics of any particular decision or system. In short, they are inherent in BI systems that are based on data – which includes most systems in operation.
Programmable and non-programmable decisions
Of course, BI systems are perfectly adequate – even indispensable – for certain situations. Examples of these include, financial reporting (when done right!) and other operational reporting (inventory, logistics etc). These generally tend to be routine situations with clear cut decision criteria and well-defined processes. Simply put, they are the kinds of decisions that can be programmed.
On the other hand, many decisions cannot be programmed: they have to be made based on incomplete and/or ambiguous information that can be interpreted in a variety of ways. Examples include issues such as what an organization should do in response to increased competition or formulating a sales action plan in a rapidly changing business environment. These issues are wicked: among other things, there is a diversity of viewpoints on how they should be resolved. A business manager and a sales representative are likely to have different views on how sales action plans should be adjusted in response to a changing business environment. The shortcomings of BI systems become particularly obvious when dealing with such problems.
Some may argue that it is naïve to expect BI systems to be able to handle such problems. I agree entirely. However, it is easy to overlook over the limitations of these systems, particularly when called upon to make snap decisions on complex matters. Moreover, any critical reflection regarding what BI ought to be is drowned in a deluge of vendor propaganda and advertisements masquerading as independent advice in the pages of BI trade journals.
Conclusion
In this article I have argued that BI systems have some inherent limitations as decision support tools because they focus attention on data to the exclusion of other, equally important factors. Although the data-centric paradigm promoted by these systems is adequate for routine matters, it falls short when applied to complex decision problems.
Not on the same page, not even reading the same book
In the course of a project it is not uncommon to have stakeholders with conflicting viewpoints on a particular issue. Some examples of this include:
- The sponsor who wants a set of reports done in a day and the report writer who reckons it will take a week.
- The project manager who believes that tasks can be tracked to a very fine level and the developer who “knows” they can’t.
- The developer who is convinced that method A is the best way to go and her colleague who is equally certain that method B is the way to go.
These are but a small selection of the conflicts I have encountered in my work. Most project professionals would undoubtedly have had similar experiences. It can be difficult to reconcile such conflicting viewpoints because they are based on completely different worldviews. Unless these are made explicit, it is difficult to come to for those involved to understand each other let alone agree.
Consider, for example, the first case above: the sponsor’s worldview is likely based on his reality, perhaps a deadline imposed on him by his boss , whereas the report writer’s view is based on what she thinks is a reasonable time to create the reports requested.
Metaphorically, the two parties are not on the same page. Worse, they are not even reading the same book. The sponsor’s reality – his “book” – is based on an imposed deadline whereas the report writer’s is based on an estimate.
So, how does one get the two sides to understand each other’s point of view?
The metaphor gives us a clue – we have to first get them to understand that they are “reading from different books.” Only then do they have a hope in hell of understanding each other’s storylines.
This isn’t easy because people tend to believe their views are reasonable (even when they aren’t!). The only way to resolve these differences are through dialogue or collective deliberation. As I have written in my post on rational dialogue in project environments:
Someone recently mentioned to me that the problem in project meetings (and indeed any conversation) is that participants see their own positions as being rational, even when they are not. Consequently, they stick to their views, even when faced with evidence to the contrary. However, such folks aren’t being rational because they do not subject their positions and views to “trial by argumentation.” Rationality lies in dialogue, not in individual statements or positions. A productive discussion is one in which conflicting claims are debated until they converge on an optimal decision. The best (or most rational) position is one that emerges from such collective deliberation.
The point is a simple one: we have to get the two sides talking to each other, with each one accepting that their views may need to be revised in the light of the arguments presented by the other. Dialogue Mapping, which I have discussed in many posts on this blog is a great way to facilitate such dialogue.
In our forthcoming book entitled, The Heretic’s Guide to Best Practices, Paul Culmsee and I describe Dialogue Mapping and a host of other techniques that can help organisations tackle problems associated with people who are “not on the same page” or “reading different books.”
The book is currently in the second round of proofs. We’ll soon be putting up a website with excerpts, review comments, pricing, release dates and much more – stay tuned!


