Archive for the ‘Probability’ Category
Cox’s risk matrix theorem and its implications for project risk management
Introduction
One of the standard ways of characterising risk on projects is to use matrices which categorise risks by impact and probability of occurrence. These matrices provide a qualitative risk ranking in categories such as high, medium and low (or colour: red, yellow and green). Such rankings are often used to prioritise and allocate resources to manage risks. There is a widespread belief that the qualitative ranking provided by matrices reflects an underlying quantitative ranking. In a paper entitled, What’s wrong with risk matrices?, Tony Cox shows that the qualitative risk ranking provided by a risk matrix will agree with the quantitative risk ranking only if the matrix is constructed according to certain general principles. This post is devoted to an exposition of these principles and their consequences.
Since the content of this post may seem overly academic to some of my readers, I think it is worth clarifying why I believe an understanding of Cox’s principles is important for project managers. First, 3×3 and 4×4 risk matrices are widely used in managing project risk. Typically these matrices are constructed in an intuitive (but arbitrary) manner. Cox shows – using very general assumptions – that there is only one sensible colouring scheme (or form) of these matrices. This conclusion was surprising to me, and I think that many readers may also find it so. Second, and possibly more important, is that the arguments presented in the paper show that it is impossible to maintain perfect congruence between qualitative (matrix) and quantitative rankings. As I discuss later, this is essentially due to the impossibility of representing quantitative rankings accurately on a rectangular grid. Developing an understanding of these points will enable project managers to use risk matrices in a more logically sound manner.
Background and preliminaries
Let’s begin with some terminology that’s well known to most project managers:
Probability: This is the likelihood that a risk will occur. It is quantified as a number between 0 (will definitely not occur) and 1 (will definitely occur).
Impact (termed “consequence” in the paper): This is the severity of the risk should it occur. It can also be quantified as a number between 0 (lowest severity) and 1(highest severity).
Note that the above scales for probability and impact are arbitrary – other common choices are percentages or a scale of 0 to 10.
Risk: In many project risk management frameworks, risk is characterised by the formula: Risk = probability x impact. This formula looks reasonable, but is typically specified a priori, without any justification.
A risk can be plotted on a two dimensional graph depicting impact (on the x-axis) and probability (on the y-axis). This is typically where the problems start: for most risks, neither the probability nor the impact can be accurately quantified. The standard solution is to use a qualitative scale, where instead of numbers one uses descriptive text – for example, the probability, impact and risk can take on one of three values: high, medium and low (as shown in Figure 1 below). In doing this, analysts make the implicit assumption that the categorisation provided by the qualitative assessment ranks the risks in correct quantitative order. Problem is, this isn’t true.

Figure 1: A 3x3 Risk Matrix
Let’s look at the simple case of two risks A and B ranked on a 2×2 risk matrix shown in Figure 2 below. Let’s assume that the probability and impact of each of the two risks are independent and uniformly distributed between 0 and 1. Clearly, if the two risks have the same qualitative ranking (high, say), there is no way to rank them correctly unless one has quantitative knowledge of probability and impact – which is usually not the case. In the absence of this information, there’s a 50% chance (all other factors being equal) of ranking them correctly – i.e. one is effectively “flipping a coin” to choose which one has the higher (or lower) rank. This situation highlights a shortcoming of risk matrices: poor resolution. It is not possible to rank risks that have the same qualitative ranking.

Figure 2: A 2x2 Risk Matrix
“That’s obvious,” I hear you say – and you’re right. But there’s more: if one of the ratings is medium and the other one is not (i.e. the other one is high or low), then there is a non-zero chance of making an incorrect ranking because some points in the cell with the higher qualitative rating have a lower quantitative value of risk than some points in the cell with the lower qualitative ranking. Look at that statement again: it implies that risk matrices can incorrectly assign higher qualitative rankings to quantitatively smaller risks – i.e. there is the possibility of making ranking errors. This point is seriously counter-intuitive (to me anyway) and merits a proof, which Cox provides and I discuss below. Before doing so, I should also point out that the discussion of this paragraph assumes that the probabilities and impacts of the two risks are independent and uniformly distributed. Cox also points out that the chance of making the wrong ranking can be even higher if the joint distribution of the two are correlated. In particular, if the correlation is negative (i.e. probability decreases as impact increases), a random ranking is actually better than that provided by the risk matrix. In this situation the information provided by risk matrices is “worse than useless” (a random choice is better!). Negative correlations between probability and impact are actually quite common – many situations involve a mix of high probability-low impact and low probability-high impact risks. See the paper for more on this.
Weak consistency and its implications
With the issues of poor resolution and ranking errors established, Cox asks the question: What can be salvaged? The underlying problem is that the joint distribution of probability and impact is unknown. The standard approach to improving the utility of risk matrices is to attempt to characterise this distribution. This can be done using artificial intelligence tools – and Cox provides references to papers that use some of these techniques to characterise distributions. These techniques typically need plentiful data as they attempt to infer characteristics of the joint distribution from data points. Cox, instead, proposes an approach that is based on general properties of risk matrices – i.e. an approach that prescribes a set of rules that ensure consistency. This has the advantage of being general, and not depending on the availability of data points to characterise the probability distribution.
So what might a consistency criterion look like? Cox suggests that, at the very least, a risk matrix should be able to distinguish reliably between very high and very low risks. He formalises this requirement in his definition of weak consistency, which I quote from the paper:
A risk matrix with more than one “colour” (level of risk priority) for its cells satisfies weak consistency with a quantitative risk interpretation if points in its top risk category (red) represent higher quantitative risks than points in its bottom category (green)
The notion of weak consistency formalises the intuitive expectation that a risk matrix must, at the very least, distinguish between the lowest and highest (quantitative) risks. If it can’t, it is indeed “worse than useless”. Note that weak consistency doesn’t say anything about distinguishing between medium and lowest/highest risks – merely between the lowest and highest.
Having defined weak consistency, Cox derives some of its surprising consequences, which I describe next.
Cox’s First Lemma: If a risk matrix satisfies weak consistency, then no red cell (highest risk category) can share an edge with a green cell (lowest risk category).
Proof: To see how this is plausible, consider the different ways in which a red cell can adjoin a green one. Basically there are only two ways in which this can happen, which I’ve illustrated in Figure 3. Now assume that the quantitative risk of the midpoint of the common edge is a number n (n between 0 and 1). Then if x and y and are the impact and probability, we have
xy=n or y=n/x
So, the locus of all points having the same risk (often called the iso-risk contour) as the midpoint is a rectangular hyperbola with negative slope (i.e. y decreases as x increases). The negative slope (see Figure 3) implies that the points above the iso-risk contour in the green cell have a higher quantitative risk than points below the contour in the red cell. This contradicts weak consistency. Hence – by reductio ad absurdum – it isn’t possible to have a green cell and a red cell with a common edge.

Figure 3: Figure for Lemma 1
Cox’s Second Lemma: if a risk matrix satisfies weak consistency and has at least two colours (green in lower left and red in upper right, if axes are oriented to depict increasing probability and impact), then no red cell can occur in the bottom row or left column of the matrix.
Proof: Assume it is possible to have a red cell in the bottom row or left column. Now consider an iso-risk contour for a sufficiently small risk (i.e. a contour that passes through the lower left-most green cell). By the properties of rectangular hyperbolas, this contour must pass through all cells in the bottom row and the left-most column, as shown in Figure 4. Thus, by an argument similar to the one of the previous lemma, all points below the iso-risk contour in either of the red cells have a smaller quantitative risk than point above it in the green cell. This violates weak consistency, and hence the assumption is incorrect.

Figure 4: Figure for Lemma 2
An implication that follows directly from the above lemmas is that any risk matrix that satisfies weak consistency must have at least three colours!
Surprised? I certainly was when I first read this.
Between-ness and its implications
If a risk matrix provides a qualitative representation of the actual qualitative risks, then small changes in the probability or impact should not cause discontinuous jumps in risk categorisation from lowest to highest category without going through the intermediate category. (Recall, from the previous section, that a weakly consistent matrix must have at least three colours).
This expectation is formalised in the axiom of between-ness:
A risk matrix satisfies the axiom of between-ness if every positively sloped line segment that lies in a green cell at its lower end and a red cell at its upper end must pass through at least one intermediate cell (i.e. one that is neither red nor green).
By definition, no 2×2 cell can satisfy between-ness. Further, amongst 3×3 matrices, only one colour scheme satisfies both weak consistency and between-ness. This is the matrix shown in Figure 1: green in the left and bottom columns , red in upper right-most cell and yellow in all other cells. This, to me, is a truly amazing consequence of a couple of simple, intuitive axioms.
Consistent colouring and its implications
The basic idea behind consistent colouring is that risks that have the identical quantitative values should have the same qualitative ratings. This is impossible to achieve in a discrete risk matrix because iso-risk contours cannot coincide with cell boundaries (Why? Because iso-risk contours have negative slopes whereas cell boundaries have zero or infinite slope – i.e. they are horizontal or vertical lines). So, Cox suggests the following: enforce consistent colouring for extreme categories only – red and green – allowing violations for intermediate categories. What this means is that cells that contain iso-risk contours which pass through other red cells (“red contours”) must be red and cells that contain iso-risk contours which pass through other green cells (“green contours”) must be green. Hence the following definition of consistent colouring:
- A cell is red if it contains points with quantitative risks at least as high as those in other red cells, and does not contain points with quantitative risks as small as those on any green cell.
- A cell is green if it contains points with risks at least as small as those in other green cells, and does not contain points with quantitative risks as high as those in any red cell.
- A cell has an intermediate colour only if it a) lies between a red cell and a green cell or b) it contains points with quantitative risks higher than those in some red cells and also points with quantitative risks lower than those in some green cells.
An iso-risk contour is green if it passes through one or more green cells but no red cells and a red contour is one which passes through one or more red cells but no green cells. Consistent colouring then implies that cells with red contours and no green contours are red; and cells with green contours and no red contours are green (and, obviously, cells with contours of both colours are intermediate)
Implications of the three axioms – Cox’s Risk Matrix Theorem
So, after a longish journey, we have three axioms: weak consistency, between-ness and consistent colouring. With that done, Cox rolls out his theorem – which I dub Cox’s Risk Matrix Theorem (not to be confused with Cox’s Theorem from statistics!), which can be stated as follows:
In a risk matrix satisfying weak consistency, between-ness and consistent colouring:
a) All cells in the leftmost column and in the bottom row are green.
b) All cells in the second column from the left and the second row from the bottom are non-red.
The proof is a bit long, so I’ll omit it, making a couple of plausibility arguments instead:
- The lower leftmost cell is green (by definition), and consistent colouring implies that all contours that lie below the one passing through the upper right corner of this cell must also be green because a) they pass through the lower leftmost cell which is green and b) none of the other cells they pass through are red (by Cox’s second lemma). The other cells on the lowest or leftmost edge of the matrix can only be intermediate or green. That they cannot be intermediate is a consequence of between-ness.
- That the second row and second column must be non-red is also easy to see: assume any of these cells to be red. We then have a red cell adjoining a green cell, which violates between-ness.
I’ll leave it at that, referring the interested reader to the paper for a complete proof.
Cox’s theorem has an immediate corollary which is particularly interesting for project managers who use 3×3 and 4×4 risk matrices:
A tricoloured 3×3 or 4×4 matrix that satisfies weak consistency, between-ness and consistent colouring can have only the following (single!) colour scheme:
a) Leftmost column and bottom row coloured green.
b) Top right cell (for 3×3) or four top right cells (for 4×4) coloured red.
c) All other cells coloured yellow.
Proof: Cox’s theorem implies that the leftmost column and bottom row are green. The top right cell must be red (since it is a tricoloured matrix). Consistent colouring implies that the two cells adjoining this cell (in a 4×4 matrix) and the one diagonally adjacent must also be red (this cannot be so for a 3×3 matrix because these cells would adjoin a green cell which violates Cox’s first lemma). All other cells must be yellow by between-ness.
This result is quite amazing. From three very intuitive axioms Cox derives essentially the only possible colouring scheme for 3×3 and 4×4 risk matrices.
Conclusion
This brings me to the end of this post on the Cox’s axiomatic approach to building logically consistent risk matrices. I highly recommend reading the original paper for more. Although it presents some fairly involved arguments, it is very well written. The arguments are presented with clarity and logical surefootedness, and the assumptions underlying each argument are clearly laid out. The three principles (or axioms) proposed are intuitively appealing – even obvious – but their consequences are quite unexpected (witness the unique colouring scheme for 3×3 and 4×4 matrices). Further, the arguments leading up to the lemmas and theorems bring up points that are worth bearing in mind when using risk matrices in practical situations.
In closing I should mention that the paper also discusses some other limitations of risk matrices that flow from these principles: in particular, spurious risk resolution and inappropriate resource allocation based on qualitative risk categorisation. For reasons of space, and the very high likelihood that I’ve already tested my readers’ patience to near (if not beyond) breaking point, I’ll defer a discussion of these to a future post.
Note added on 20 December, 2009:
See this post for a visual representation of the above discussion of Cox’s risk matrix theorem and the comments that follow.
On the inherent uncertainty of project tasks estimates
The accuracy of a project schedule depends on the accuracy of the individual activity (or task) duration estimates that go into it. Project managers know this from (often bitter) experience. Treatises such as the gospel according to PMBOK recognise this, and exhort project managers to estimate uncertainties and include them when reporting activity durations. However, the same books have little to say on how these uncertainties should be integrated into the project schedule in a meaningful way. Sure, well-established techniques such as PERT do incorporate probabilities into schedules via averaged or expected durations. But the resulting schedules are always treated as deterministic, with each task (and hence, the project) having a definite completion date. Schedules rarely, if ever, make explicit allowance for uncertainties.
In this post I look into the nature of uncertainty in project tasks – in particular I focus on the probability distribution of task durations. My approach is intuitive and somewhat naive. Having said that up front, I trust purists and pedants will bear with my somewhat loose use of terminology relating to probability theory.
Theory is good for theorists; practitioners prefer examples, so I’ll start with one. Consider an activity that you do regularly – such as getting ready in the morning. Since you’ve done it so often, you have a pretty good idea how long it takes on average. Say it takes you an hour on average – from when you get out of bed to when you walk out of your front door. Clearly, on a particular day you could be super-quick and finish in 45 minutes, or even 40 minutes. However, there’s a lower limit to the early finish – you can’t get ready in 0 minutes! Let’s say the lower limit is 30 minutes. On the other hand, there’s really no upper limit. On a bad day you could take a few hours. Or if you slip in the shower and hurt your back, you could take a few days! So, in terms of probabilities, we have a 0% probability at a lower limit and also at infinity (since the probability of taking an infinite time to get to work is essentially zero). In between we’d expect the probability to hit a maximum at a lowish value of time (may be 50 minutes or so). Beyond the maximum, the probability would decay rapidly at first, then slowly becoming zero at an infinite time.
If we were to plot the probability of activity completion for this example as a function of time, it would look like the long-tailed function I’ve depicted in Figure 1 below. The distribution starts at a non-zero cutoff (corresponding to the minimum time for the activity); increases to a maximum (corresponding to the most probable time); and then falls off rapidly at first, then with a long, slowly decaying tail. The mean (or average) of the distribution is located to the right of the maximum because of the long tail. In the example, 
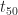

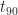

It turns out that many phenomena can be modeled by this kind of long-tailed distribution. Some of the better known long-tailed distributions include lognormal and power law distributions. A quick, informal review of project management literature revealed that lognormal distributions are more commonly used than power laws to model activity duration uncertainties. This may be because lognormal distributions have a finite mean and variance whereas power law distributions can have infinite values for both (see this presentation by Michael Mitzenmacher, for example). [An Aside:If you’re curious as to why infinities are possible in the latter, it is because power laws decay more slowly than lognormal distributions – i.e they have “fatter” tails, and hence enclose larger (even infinite) areas.]. In any case, regardless of the exact form of the distribution for activity durations, what’s important and non-controversial is the short cutoff, the peak and long, decaying tail. These characteristics are true of all probability distributions that describe activity durations.
There’s one immediate consequence of the long tail: if you want to be really, really sure of completing any activity, you have to add a lot of “air” or safety because there’s a chance that you may “slip in the shower” so to speak. Hence, many activity estimators add large buffers to their estimates. Project managers who suffer the consequences of the resulting inaccurate schedule are thus victims of the tail.
Very few methodologies explicitly acknowledge uncertainty in activity estimates, let alone present ways to deal with it. Those that do include The Critical Chain Method, Monte Carlo Simulation and Evidence Based Scheduling. The Critical Chain technique deals with uncertainty by slashing estimates to their
(Note: Portions of this post are based on my article on the Critical Chain Method)


